在实时通信服务中,有很多应用程序都带有语音识别功能。比如实时字幕、实时翻译、语音命令或存储/汇总音频对话等。
几个月前在Hangouts Meet,实时字幕的语音识别功能已经上线了。但最近这个选项被提升到主要用户界面中。那之后我几乎每天都在使用它。

我最感兴趣的是识别技术,尤其是对于如何将DeepSpeech集成到RTC媒体服务器中以提供一个性价比高的解决方案。但是在这篇文章中识别技术不是主题。我想花一些时间从信号的角度分析在Hangouts Meet 中如何实现实时字幕。
RTC高级服务中至少有三种可用的语音识别结构:
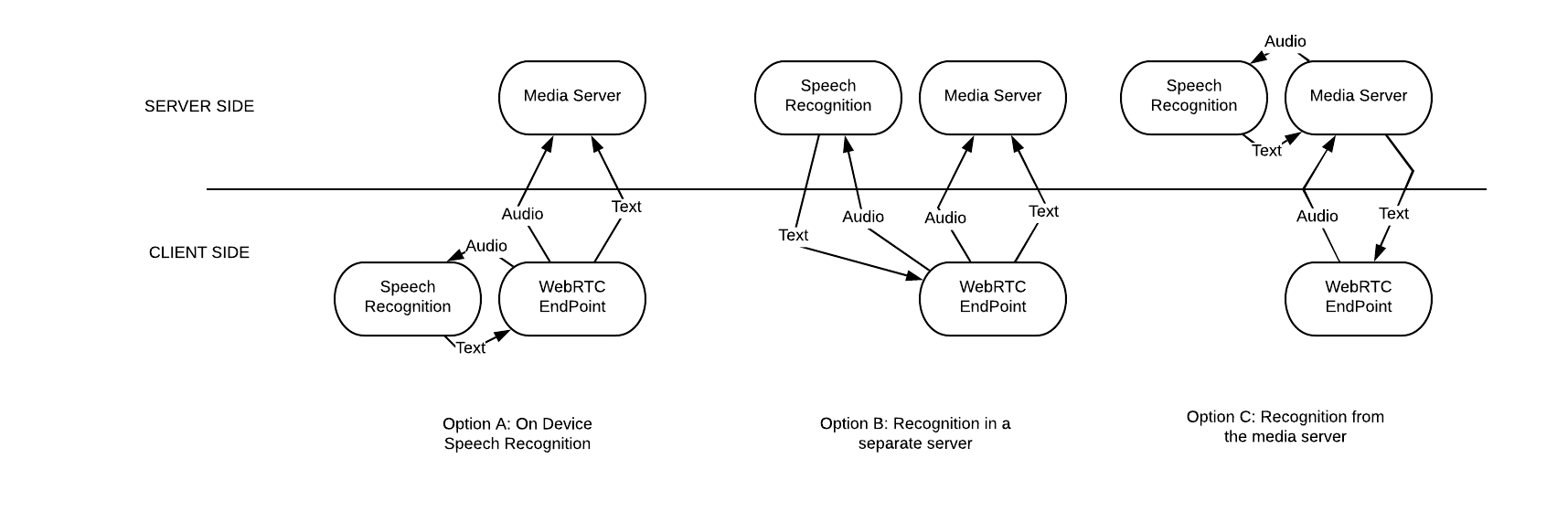
A)设备中的语音识别:这是成本最低的方案。但并非所有设备都支持语音识别,模型的质量不如云模型的好,并且需要一定的CPU空间。这对某些不能满足上述条件的设备是个问题。
B)单独服务器中的识别:这种方案是种低效的网络传输。因为客户端需要同时发送两次音频。这对服务供应商而言成本太高。但不需要在媒体服务器中进行更改。
C)从媒体服务器中识别:从客户端和网络的角度来看这都是非常有效的一种方案。但是这种方案需要媒体服务器做出一定更改。所以服务提供商的成本会很高。
鉴于Google拥有自己的语音识别技术,并且成本不是他们最关注的问题。所以休息聚会中最合理的方案应该是方案(C)。我尝试使用这种方案来搞清楚转录的文字是如何在媒体服务器和浏览器之间传输的。
我所做的第一件事是查看会话期间的压缩代码和Hangouts Meet 网页发送的HTTP请求。但是我并没有找到。所以我用语音搜索了“stt 、transcription、recognition”或相似字眼。在连接到Hangouts时,我还在浏览器控制台中运行了一个非常简单的WebSpeech代码段。对于Hangouts页面和设备上的识别来说,产生的结果不尽相同。(页面中的效果更好)。
接下来我决定试一试chrome:// webrtc-internals和voilà中的DataChannels,我在讲话时接收到了很多消息。所以这些消息应该是语音识别的具体内容。
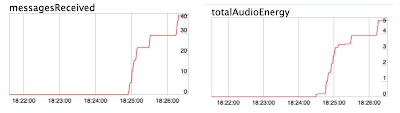
之后我查看了一些webrtc-internals事件。我发现如果你不在首次登陆Hangouts Meet时默认始终打开DataChannel的话。Webrtc为首次激活字幕功能的用户设定了一个专用的DataChannel。

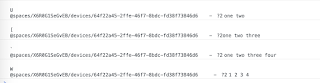
为了尝试找出该DataChannel的确切选项以及消息中发送的信息格式,我用自己的API替换了RTCPeerConnection.createDataChannel 的API。以便能够使用浏览器控制台中的此简单代码段拦截这些调用。
通过这个工具,我发现:为识别字幕创建的DataChannel存在一定风险,并且是使用代码maxRetransmissions = 10创建的。其有效载荷是二进制数据,可能是protobuf格式。 但我们仍然可以将其转换为字符串和几个带有用户ID和文本的字段:
原文地址:http://www.rtcbits.com/2019/10/speech-recognition-in-hangouts-meet.html?m=1
