2021-06-15更新
音频数据还有一点很奇怪:音频ssrc 78925910在统计图中出现了两次,一次作为入站数据出现:
另一次作为出站数据出现:
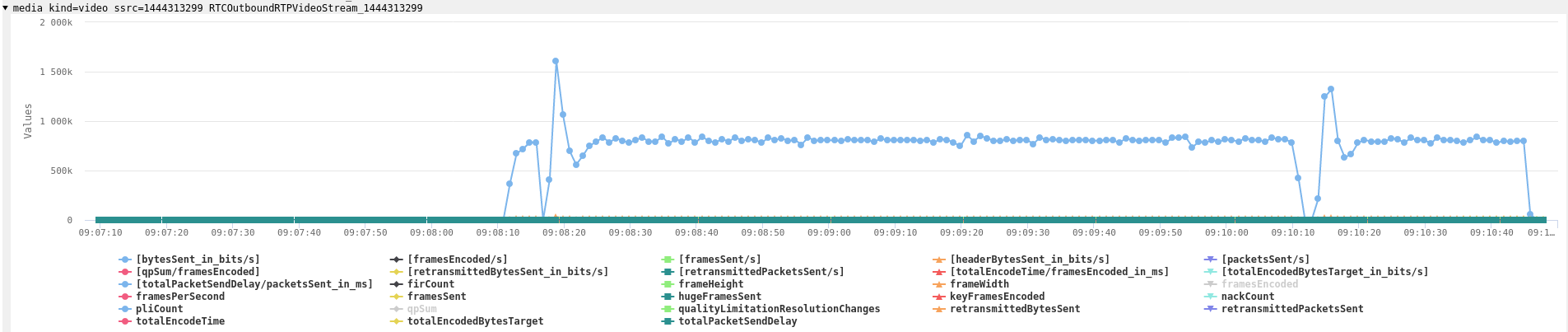
RTP转储清楚地表明,服务器并没有用该SSRC发送任何音频数据包。它是浏览器在第一次调用createAnswer和setLocalDescription时产生的,随后服务器在setRemoteDescription调用中使用了它。技术上讲,这是一个SSRC冲突,浏览器应该拒绝,且这样做也没有意义。算是又一个小错误吧。
但RTCP的统计数据显示,还有另外两个错误:
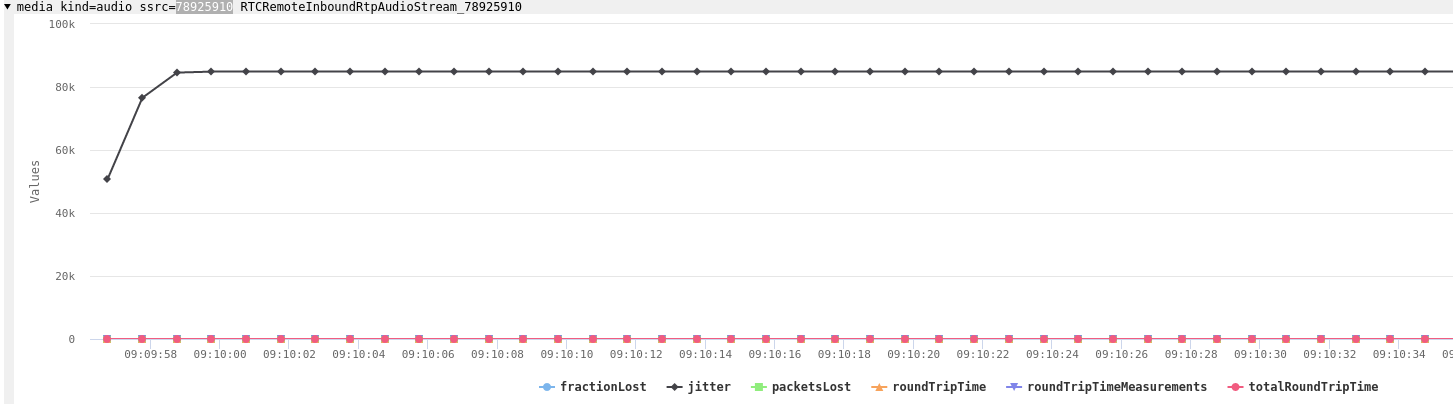
一般不会出现如此高的抖动值。因为抖动是以秒为单位的,超过半秒就意味着糟糕的通话质量。
原来,往返时间一直为零也是个错误。自上次接收者报告后,RTCP接收器报告中的时间就被设置为零了。
Main JavaScript
我们在此处找到了Main.js 文件(注:该链接有时可能失效)。
RTCPeerConnection的构造函数比较容易找到,具体如下:
this.rtcPeerConnection = new RTCPeerConnection({
rtcpMuxPolicy: "require",
bundlePolicy: "max-bundle",
encodedInsertableStreams: !0
}),
this.dataChannel = new l.QRDataChannel(this.delegate,this,
this.rtcPeerConnection.createDataChannel("0"),this.sessionDescription),
this.midMap = new c.MIDMap,
this.sdpModifyLock = new i.Mutex(!0),
this.conversationSdpBuilder = new p.ConversationSDPBuilder,
this.transceiverInfoMap = new Map,
this.conversation = {
us: (0,
s.participantDescriptionForTiers)(this.participantId, [], []),
them: []
},
this.unlisteners = [],
this.ourActiveStreamIds = [],
其中一些变量的命名很高明。MIDMap就说明FaceTime正在使用收发器的mid属性来部署,追踪参与者。Mozilla的Jan-Ivar在2018年就提议了这项操作。
但我认为,a=msid线和流ID是种更易管理的方式。
updateVideoTrack和updateAudioTrack则表明,两者大量使用了RTCRtpSender.setParameters API来启用和禁用不同的音频和视频流。注意 “getAudioTierForStreamIndex “的命名:
async updateAudioTrack(e, t) {
var n, r;
const [i] = null !== (r = null === (n = this.mediaStreamManager) || void 0 === n ? void 0 : n.getAudioTracks()) && void 0 !== r ? r : [];
if (i && i.enabled && this.ourActiveStreamIds.includes(t.streamID)) {
const n = (0, a.getAudioTierForStreamIndex)(t.streamIndex),
r = e.sender.getParameters();
await e.sender.setParameters({
...r,
encodings: r.encodings.map(e => ({
...e,
maxBitrate: n.encodingBitrate,
active: !0
}))
}), await e.sender.replaceTrack(i)
} else await e.sender.replaceTrack(null)
}
SDP应该是在客户端的conversationSDPBuilder对象中生成的。二进制信令太小,无法包含完整的统一计划SDP。
conversationSDPBuilder也有标示表明:至少,现在正在测试更好的transport-wide congestion control(简称twcc)。
但其中也混有一些SDP(甚至使用了正则表达式),这点令人咋舌。它相当有限,如下:
_mungeSDP(e) {
let t = e.replace(/ssrc-audio-level$/gm, "ssrc-audio-level vad=off");
return t = t.replace(/profile-level-id=42[0-9a-zA-Z]{4}$/gm, "profile-level-id=42e01f"),
t
}
上述操作属于non-standard,用它调用setLocalDescription之前没有必要进行这一步。
用baseline替换Chrome所选的任何H.264级别也没有必要。如果只需要baseline,应该从服务器的offer中删除profile-level-asymmetry。
ice candidate是静态创建的,如下所示:
createCandidate(e) {
const t = e.connectionParameters;
return t ? `1 1 udp 1 ${t.serverIP} ${t.serverPort} typ host` : void 0
}
上文“制约因素”部分提到过目前只支持UDP,这在本文所述的企业中不太可能发挥作用。FaceTime开发者需要注意Chrome的WebRTC错误,标准中说应该是大写的 UDP。
搜索“createEncodedStreams ”会显示Insertable Streams API在哪里启用。它试图使用较新版本的API,但现在Chrome的实现也很好。这也是其缺乏火狐支持的原因。因为火狐的目标是实现较新版本的规范,Safari也是如此。
接下来让我们看看worker和其使用的端到端加密。
JavaScript Worker
我去年就推荐大家用worker进行加密和解密,因为这些工具在开发者工具中就很容易找到,而且通常都独立成篇。下文所示的工具也是如此,简化后的版本不到1750行。
端到端加密使用了IETF draft中描述的SFrame方案。这并不奇怪。因为其中一位开发者最近离开谷歌加入了苹果,负责FaceTime开发的工作。
在解密功能中缺乏simulcast,和insertable streams如何相互作用这两点都值得探讨。每当SSRC上接收到一个帧,一个notifyOnFirstRecentFrameReceived method就会被调用。
async decrypt(e, t) {
if (this.framesReceived++, void 0 === t && (t = this.ssrc), t !== this.ssrc && (this.ssrc = t, this.lastReceivedFrameTime = 0, this.lastDecryptedFrameTime = 0), void 0 === t) return new Error(`Receiver[${this.id}]: no ssrc for frame`);
this.notifyOnFirstRecentFrameReceived();
const s = await this.receiver.decrypt(e, t);
return s instanceof Error || (this.framesDecrypted++, this.lastDecryptedFrameTime = Date.now()), s;
}
不采用追溯的话,我推测它会回到Main.js 文件,然后根据使用的poor-man’s-simulcast
层,选择一个视频对象来显示。该操作应该可以正常运行,不会出现大的故障。这是一种相当牛的技术,我期待下个月在Javascript fiddle中继续对其进行探索。目前来看用户体验非常不错。
它确实让FaceTime避免了SSRC重写的复杂性,毕竟在此之前,SFU在处理simulcast时必须进行SSRC重写。
这一点也值得讨论——使用带有H.264的 Insertable Streams时会产生一个已知问题。那就是即使你百般小心,没有加密NAL头,关键帧检测也不起作用。这是WebRTC库的一个已知bug。
这一问题可以通过不加密H.264数据包的前几个字节来避免。据推测,若出现这种情况,服务器会通过上述操作避免错误,我们可以在RTP转储中进行检查。但其实在发送时不用担心这一点。因为这只是WebRTC库的一个错误,FaceTime服务器并不会犯同样的错误。
下面我们来看看数据包转储。
SCTP转储
Chrome早就提供了在解密数据通道数据包后,进行SCTP数据包转储的方法。参见sctp_transport代码中的说明。该方法很实用。所以在刚刚公布的新dcSCTP库中被重新实现了。
我们可以看到以上述方式交换得出的数据通道消息,但是通过覆盖RTCDataChannel原型,我们有更简单查看数据的方法。但这没什么值得讨论的。真正值得一讲的是第一个数据包集合中的一个数据包。
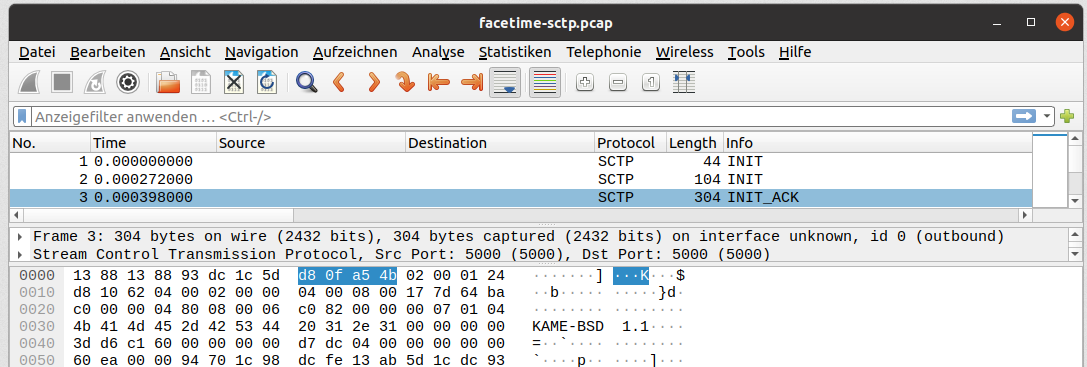
在服务器响应中,KAME-BSD 1.1这个字符串非常突出。
这表明服务器正在使用usrsctp库,该库把这个数据包作为一个version string。
希望FaceTime团队能注意到,最近针对其操作的CVE-2021-30523刚刚在Chrome 91中更新了。
最后要向大家介绍的是RTP转储。
RTP转储
我一直期待能直接从Chrome浏览器中转储RTP数据包,不必跳过这篇视频回放文章中提到的障碍。2020年年底,我借由开始了这方面的研究,并将该功能添加到了WebRTC。
简而言之,开发者必须用 –enable-logging –v=3 –force-fieldtrials=WebRTC-Debugging-RtpDump/Enabled启动Chrome,并提取日志中的RTP_PACKET行,然后将其转换为PCAP以方便检查。
但我们不能分享这些转储,因为Dag-Inge和我希望能私下保留当时各项有关内容。
我们会将转储用于两件事:
- 检查服务器是否每次只发送了一个音频流;
- 检查加密的H264帧
对于音频来说,这意味着我们要过滤产生转储的两个ssrcs。
rtp.ssrc eq 1095248263 or rtp.ssrc eq 2285848791
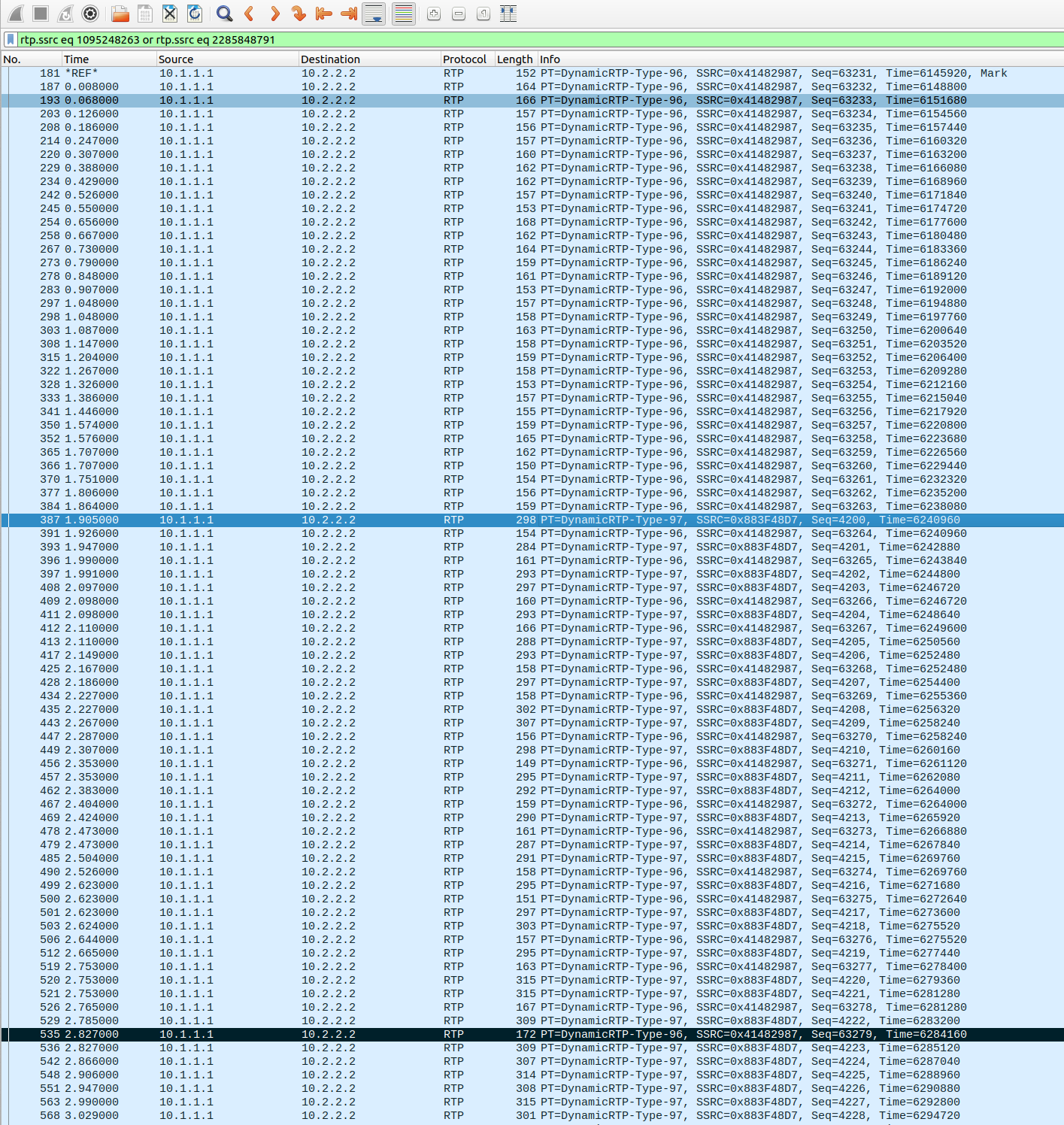
我们能看到,当客户端收到两个音频流时,二者有短暂的一秒钟重叠。他们的RTP时间戳对于第一帧的97有效载荷类型是相同的。这样客户端就可以无缝切换,并使用Insertable Streams丢弃 “旧”帧。
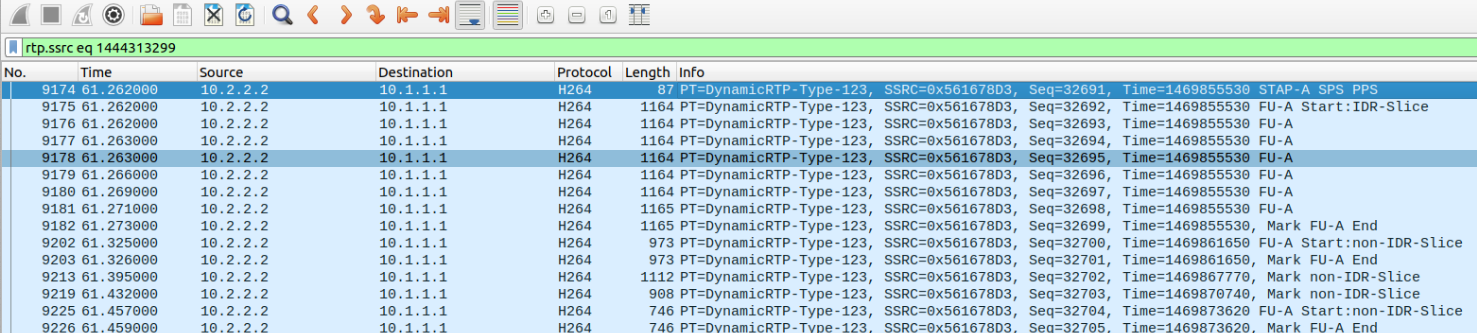
对于视频数据包,我们可以查看rtp.ssrc eq 3633224106,并配置Wireshark优秀的H.264分析器,把有效载荷类型123解码为H.264。这显示了带有SPS和PPS的STAP-A NALU的通常序列,跨越三个数据包并包含IDR(关键帧)的FU-A,以及一个单片NALU,其图片小到可以装入一个UDP数据包。更高的分辨率流使用FU-A NALU来切分图片。这表明发送方没有对NAL header进行加密,绕过了前面提到的WebRTC错误。从零,不是随机偏移量开始RTP时间戳有点马虎,但我们有时也会这样做。
如果我们查看Chrome发送的视频,例如rtp.ssrc eq 1444313299,就能明白H.264结构被加密功能正确地保留了。
呼叫前三分钟很明显缺失来自服务器的REMB反馈,导致带宽缓慢上升,以及很典型地伴随着纯粹基于丢包(loss-based)的拥塞控制算法。
通过Wireshark能获得的STUN信息相当少,所以不能从这些信息中学习。
总结
FaceTime Web端点使用了WebRTC以及使用Insertable streams的端到端加密。它还使用了一个实用的WebRTC技术,通过API避免使用simulcast和重写服务器中的同步源。
虽然我把这称为“poor man’s simulcast”,但它确实有效,并有可能使服务器的实现不那么复杂。实现中一个明显的问题是它基于较早的REMB带宽估计,而不是较新的transport-cc。但考虑到JavaScript代码中有些特性可能很快就会改变,所以未能及时做到。
缺乏TCP支持很难办,因为这会使在企业场景中的使用相当困难。
使用开放的Opus音频编解码器,以及端到端加密会引发这样一个问题,即原生的FaceTime客户端是否同时也在使用上述工具。如果是的话,其会在什么场景下使用。到目前为止,FaceTime一直倾向于使用AAC-LD等编解码器来完成操作。
在移动设备上将视频分辨率限制在720×720确实可行,因为额外考虑到了如耗电和屏幕旋转等因素。但在网络上,该分辨率似乎有点小。
文章地址:https://webrtchacks.com/facetime-finally-faces-webrtc-implementation-deep-dive/
原文作者:Philipp Hancke
