作者:Real Time Communications Bits(原文链接)
翻译:刘通
原标题:Improving Real Time Communications with Machine Learning
当我们谈及人工智能/机器学习(AI/ML)在实时通信(RTC)领域的应用时,常常可以把它们分成两类:
1. 服务层面:有很多功能可以加到视频会议服务中,比如参与者识别,增强现实,表情捕捉,语音转录或者音频翻译。这些功能通常都是以图像及语音识别,和语言处理为基础的。
2. 基础层面:还有很多方法将ML应用到RTC中,但不是为了提供新的功能,而是为了增强音视频传输的质量和/或稳定性。
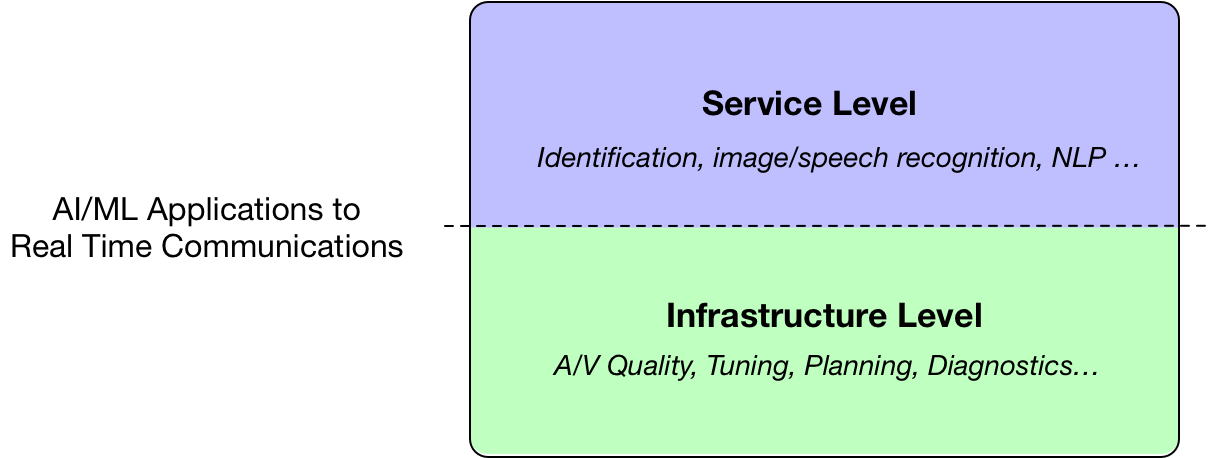
服务层面的应用虽然很有趣,但是它更像是产品经理的工作,我在下一章节中将要描述对于实时通信的基础层面上,AI/ML可以发挥哪些作用。
增强视频质量
一些用来图像识别的ML算法也可以用来增强RTC中的视频传输质量。我可以想到至少三种可以用来提高视频质量的方法。
第一种方法是为特定视频或者帧的特定部分选取最佳编码参数。举个例子,如果我们能够检测到一个场景中最重要的部分,就可以对这个区域使用更好的编码质量(更低的量化等级)。或者另一个例子,我们可以检测出信息的种类,如果是高动态视频或者典型的对话,就可以使用较好的帧率和质量。
第二个方法,通过去除那些可以由接收机重建的信息来降低必须发送的信息量。举一个极端的例子,我们都知道人类头发的形状,所以即便你知道了头发的形状,你能发送较低的质量然后在接收器中重建头发吗?此类应用的一个例子实时Google的RAISR demo。

也可以使用同样的处理来提高可读性,或者增加因为太远或者聚焦不清楚的对象的细节。
还可以在视频编码器的实现上应用机器学习来优化编码帧所需要的处理过程,VP9的代码库中就有这么一段代码。
优化音频质量
我们可以像在前一节中描述对于视频的处理一样,来消除在接收端可以重塑的冗余音频数据。在极端情况中,我们应该可以指发送文本,以及速率,接收机就应该可以基于之前学习过程中的数据来重建出几乎一样的声音。
另外一个音频质量问题是在嘈杂的环境中的语音可懂性问题。ML算法可以像Mozilla/Xiph的RRNoise项目那样通过学习从语音中分离及抑制噪声信号。
调整传输设置
RTC会话中涉及的参数量非常的大,从编码器开始就要进行非常非常多的设置,比特率,分组大小,buffer,超时等等。决定在给定的时间使用哪个参数是很困难的,并且需要要求用户/网络动态的进行改变及调整。一个基于机器学习的系统可以学习对于特定场景中的特定用户,最适合的参数组是什么。
在多方会话的场景中,用来决定如何分配可用比特率的算法是非常重要的。举个例子,是应该以50kbps同样的速率发送两个视频流,还是停止一个且以100kbps的速率发送另一个视频流。ML算法可以实时地根据所有参与方的上行/下行特点做出这类决定(比特率,帧速率,分辨率,编解码……)。
资源分配和计划

大多数的RTC基础设施都包括媒体服务器的概念。这是用来在不同参与方之间路由音视频数据包的服务器,对于多方通话来说是非常重要的。
对于这些通话,你可以使用机器学习根据服务器的地点,会话参与方的地点,以及服务器的状态来选择对于指定通话场景最合适的服务器。
它还可以用同样的方式预测负载,并确保可用资源的数量是最佳的。
分析和监测
大部分从事了一段时间构建RTC平台工作的人都经历过调试的痛苦。机器学习还可以用来debug,以及找出错误产生的根源。举个例子,基于不同参与方的质量矩阵以及服务器状态,可以诊断出这个问题是否是一个bug还是一个网络问题。
我们也可以用机器学习中的分类算法根据质量分数或者其他参数来将通话分类,以生成报告或者监测功能。
正如你看到的,机器学习可以从很多方面来提高我们RTC平台的质量和稳定性。而我所想到的只是冰山一角,还有很多点子等待开发。
