原文标题:Using ML Kit for Smile Detection
作者: “Roberto Perez“,”Gustavo Garcia”
使用ML kit进行笑脸检测
目前进行视频通话相对容易,我们可以继续对视频流做更有趣的事。伴随着机器学习的进步和越来越多的API,计算机视觉变得更容易。谷歌的ML kit是一新机器学习的实例,它基于一个库,这个库可以快速得到计算机视觉的输出结果。
为了展示如何使用谷歌ML kit 来检测实时WebRTC流中用户的笑脸, 首先要感谢webrtcHacks作者,HouseParty公司的Gustavo Garcia Bernardo. 还要感谢TokBox的移动WebRTC专家,Roberto Perez.它们教了我一些面部识别的背景知识,展示了一些代码实例,更重要的是,分享了他们在一个RTC app中准确进行面部识别的过程。
PS – tsahi和我正在进行一项关于RTC中人工智能的简短调查,如果你正在RTC环境里做一些机器学习的项目,或对此有些想法, 请花几分钟回答几个问题。

简介
就像Chad在之前的webrtcHacks文章中提到的,一个机器学习在RTC中最普遍的应用就是计算机视觉。然而除了使用面部识别来进行身份验证,跟踪等,我们还没有看到这些算法的更多实际应用。 幸运的是两周之前一篇来自Houseparty CEO Ben Rubin的评论给了我们探索人工视觉用处的机会。
同时,谷歌宣布了机器学习的跨平台移动SDK,称作ML kit. 我们想要立刻测试ML kit, 在iPhone上进行WebRTC对话,然后进行笑脸检测。
框架选择
目前有很多在设备上使用的机器学习框架和库可供人们选择,最著名的就是OpenCV,它极其成熟,当进行传统图像处理时,遇到许多特征时,这是一个跨平台的解决方案。特别是对于iOS,苹果公司去年在这个区域添加了一些API。目前它们既拥有高级的视觉框架,也拥有低级但是灵活的CoreML. 对于安卓系统,机器学习主要由Tensorflow Lite支持,然而,就像之前提到的, 谷歌最近增加了新的ML kit框架。
谷歌的ML Kit
ML Kit有几个优点。首先,它支持多平台使用,iOS和安卓都可以使用。并且,它具有不同级别的API。另外, 它提供了不同的部署和执行模型,允许在设备上和云端进行数据处理。最后,它还支持为运行于设备上的模型提供优化与更新。
实现
从视频流中提取图像
首先,为了整合ML Kit和我们的WebTC应用,需要得到图像。我们需要提取本地或远程图像(根据使用目的)并且把它们转换成ML Kit支持的正确类型。
在iOS中,ML Kit支持的图像类型为UIImage, CMSampleBufferRef.(请确保图像是面部向上的)
根据你使用的WebRTC API,有几种不同的方法来得到图像。如果你在使用 official WebRTC iOS Framework ,你可以将渲染器和本地/远程RTCVideoTrack连接起来,得到作为RTCVideoFrame的视频。这样就可以进入YUV buffers,轻松转换成UIImage类型。
如果你在使用TokBox上的API,你可以使用custom driver来得到原始本地图像。它们会被CVPixelBuffer或YUV buffer接收,并转换成UIImage类型。
面部识别API
一旦得到UIImage类型的文件,就可以传入ML Kit面部识别器,之后我们可以看到, 大多数情况下只需要传入一部分图像来减少CPU使用的影响。通过以下代码你可以看到使用ML Kit API是多么容易。
let options = VisionFaceDetectorOptions()
let faceDetector = vision.faceDetector(options: options)
let visionImage = VisionImage(image: image)
faceDetector.detect(in: visionImage) { (faces, error) in
guard error == nil, let faces = faces, !faces.isEmpty else {
return
}
for face in faces {
if face.hasSmilingProbability {
let smileProb = face.smilingProbability
if (smileProb > 0.5) {
Log.info("Smiling!", error: nil)
}
}
}
}
概率阈值
我们发现当概率阈值为0.5时,得到的结果比较符合要求。你可以在this sample app中查看完整代码,使用OpenTok来提取视频,使用以上代码检测微笑概率。
表现评估
RTC应用是资源密集型的,当把机器学习加入RTC中,资源消耗是一个主要问题。伴随着机器学习,就有了一个准确率和资源利用的平衡。本节我们从不同角度评估,当决定如何向app中引入这些特征时,对其提供指导和期望。
注意: 以下所有结果使用了iPhone 5 SE设备。
所需时间
首先要考虑的一个重要参数就是面部检测需要花费的时间。
ML Kit 有一系列参数可供设置:
1.识别模式: ML Kit 提供了两种选择- 快速/准确。
2.标志性组成: 识别眼睛,嘴巴,鼻子,耳朵。开启会使识别时间增长但会提高准确率。
3.分类: 当进行笑脸检测时,我们需要开启。
4.面部追踪: 在图片集里追踪相同的面部,开启面部追踪会使识别时间降低。
结果如下:
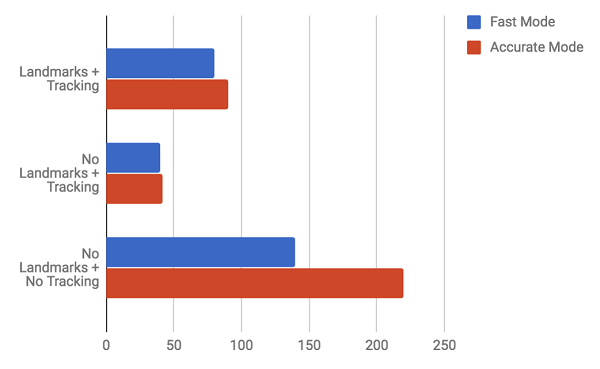
准确和快速模式的区别并不大(除非关闭面部追踪),快速模式的准确率比较好,我们决定使用以下模式结合:快速模式 + 标志性组分开启 + 面部追踪。
CPU使用
接着我们评估CPU使用。我们每秒钟大概需要处理25组图片集。我们使用时不需要对所有数据进行处理,和它相比,节省CPU/电池对我们更加重要。所以我们可以改变每秒传递给ML Kit 的用来进行识别的图片集数量。
由下图可见, 当每秒传递给ML Kit的图片集数量增加时,CPU使用几乎呈线性增长。
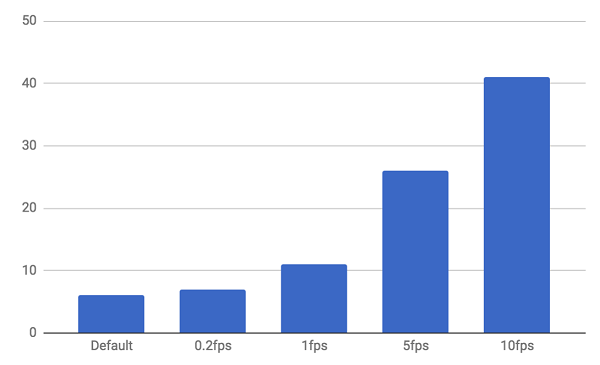
不同frame对应CPU使用率
每秒处理0.5或1个frame对CPU用量来说是比较合适的。
应用(app)大小
现在来考虑app大小,同其它app一样也需要下载,越小越好。使用了ML Kit之后, app大小只增加了15 Mb. 当只使用OpenTok时,示例app大小为46.8Mb,当加入ML Kit之后, app大小变为61.5Mb.

准确率
最终考虑到了准确率。我们首先关心的就是当ML Kit开启快速模式时,可以保证多高准确率。我们的测试基于一个移动视频会议,人们看向镜头,没有任何物体遮挡。其他情况下面部识别会变得更不可靠,更没有用。ML Kit同样支持识别一张图像中的多张人脸,但是我们没有对此进行过多测试因为在我们app的使用中,这种情况不是特别常见。
在我们测试中,算法的决定经常和人们可能会说的相差无几(至少基于我们的选择的时候)。你可以参考以下视频或直接运行示例app查看结果。
点击此处播放视频
结论
即使使用情况非常简单,这给了我们评估新的有前景的ML Kit框架的机会。这使我们看到了它的价值,和易于向我们的app中添加新计算机视觉特征的特点。在我们看来,最有意思的两个结果是:
1.这些模型令人惊讶的高准确率
2.目前不能在特定的移动设备中以最大的frame rate运行这些算法。
还有比较重要的一点是: 注意面部识别的某些情况可以用简单的图像处理算法而不用到机器学习技术。在这个角度,一些苹果的Core Image的API可能提供更好的对资源和准确率的平衡控制-至少在iOS平台中的面部识别是这样。
然而,某些情况下,传统的图像处理方法具有局限性,上文这些算法正是为此设计的。机器学习算法可以被扩展或重新训练。例如,用机器学习算法识别人的其它特性例如性别年龄等等,表现可能同样出色。这种程度的分析已经超出了传统图像分析算法可以处理的层面。
下一步
从技术的角度来看,评测的下一步将会是使用特定的模型(或许用CoreML)来分析更复杂的使用情况。我们已经有了一个想法,就是基于非理想网络状况下Generative Adversarial Networks的网络传输进行图像重建,还原。这将会是提高视频画质的一个全新方法。
