作者:Chad Hart(原文链接)
翻译:刘通
原标题:Computer Vision on the Web with WebRTC and TensorFlow
前文连接:利用WebRTC和TensorFlow通过网络实现计算机视觉1;利用WebRTC和TensorFlow通过网络实现计算机视觉2
第3部分——浏览器端
开始之前,请先在项目的根目录位置创建一个static目录。我们将从这里提供HTML和JavaScript。
现在,我们首先使用WebRTC的getUserMedia抓取一个本地摄像头Feed。从这里,我们需要将该Feed的快照发送到刚刚创建的对象检测Web API,获取结果,然后使用画布实时地在视频上显示这些结果。
HTML
我们先创建local.html文件:
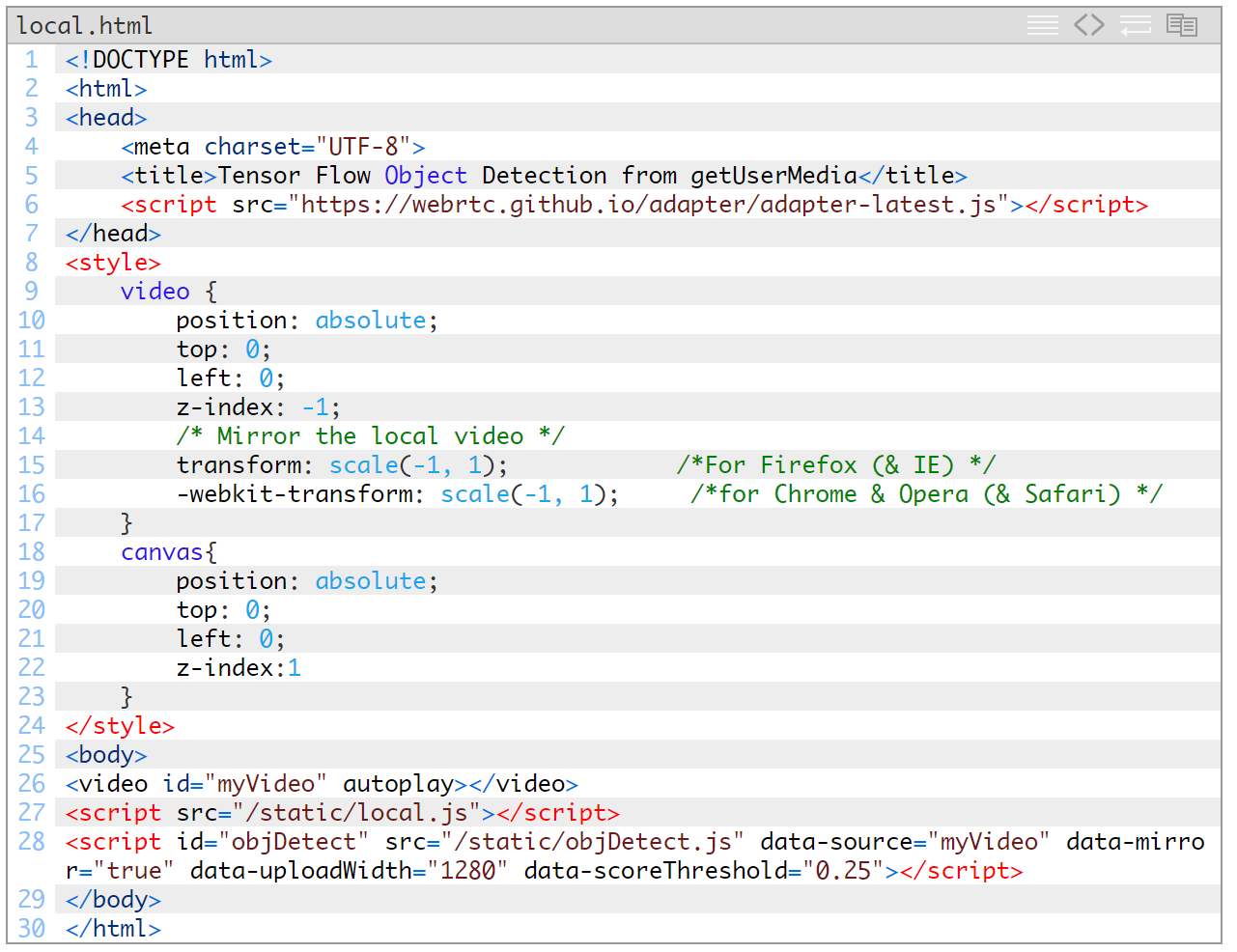
此网页的作用如下:
- 使用WebRTC adapter.js代码填充(polyfill)
-
设置一些样式,以便
- 将各个元素一个个叠加起来
- 将视频放在底部,这样我们就能使用画布在它上面绘图
- 为我们的getUserMedia流创建一个视频元素
- 链接到一个调用getUserMedia的JavaScript文件
- 链接到一个将与我们的对象检测API交互并在我们的视频上绘制方框的JavaScript文件
获取摄像头流
现在,在静态目录中创建一个local.js文件,并将下面的代码添加到该文件中:
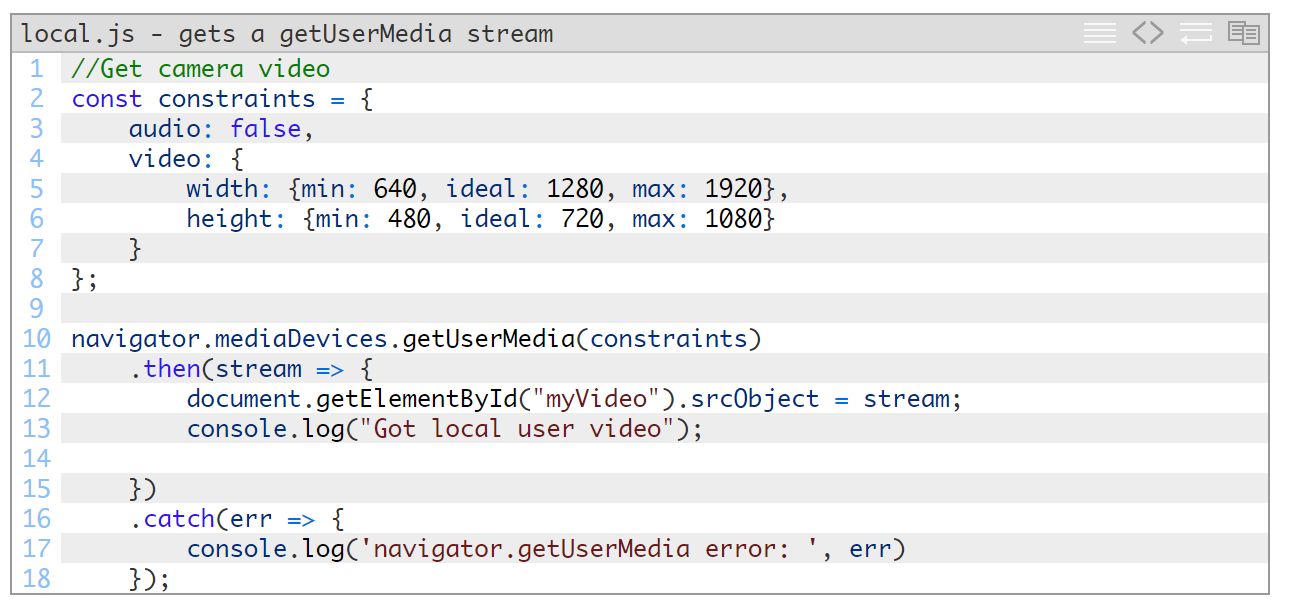
在这里您会看到我们首先设置了一些约束条件。对于我自己的情况,我需要一段1280×720视频,但要求范围在640×480与1920×1080之间。然后,我们使用这些约束条件执行getUserMedia,并将所生成的流分配给我们在HTML中创建的视频对象。
对象检测API的客户端版本
TensorFlow对象检测API教程包含了可执行以下操作的代码:获取现有图像,将其发送给实际API进行“推断”(对象检测),然后为它所看到的对象显示方框和类名。要想在浏览器中模拟这一功能,我们需要:
- 抓取图像——我们会创建一个画布来完成这一步
- 将这些图像发送给API——为此,我们会将文件作为XMLHttpRequest中form-body的一部分进行传递
- 再使用一个画布将结果绘制在我们的实时流上
要完成所有这些步骤,需要在静态文件夹中创建一个objDetect.js文件。
初始化和设置
我们需要先定义一些参数:
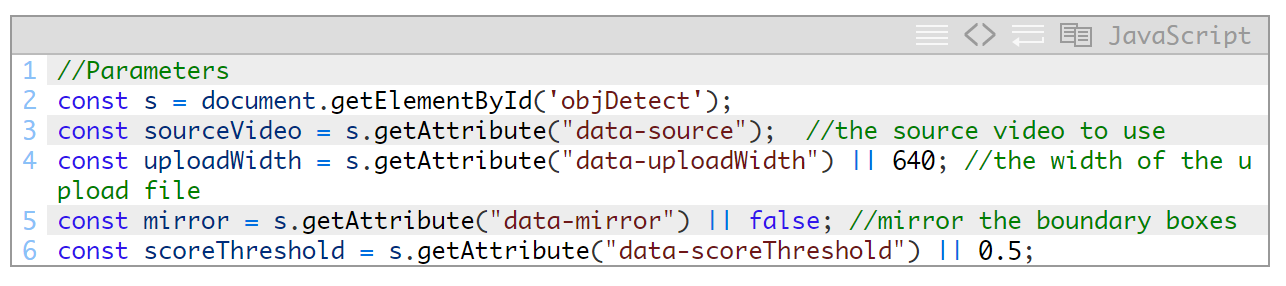
您会注意到,我将其中一些参数作为data-元素添加到了自己的HTML代码中。我最终是要在多个不同的项目中使用这段代码,并且希望重用相同的代码库,而如此添加参数就可以轻松做到这一点。待具体使用这些参数时,我会一一解释。
设置视频和画布元素
我们需要一个变量来表示我们的视频元素,需要一些起始事件,还需要创建上面提到的2个画布。

drawCanvas用于显示我们的方框和标签。imageCanvas用于向我们的对象检测API上传数据。我们需要向可见HTML添加drawCanvas,这样我们就能在绘制对象框时看到它。接下来,需要跳转到ObjDetect.js底部,逐函数向上编写。
启动该程序
触发视频事件
我们来启动该程序。首先要触发一些视频事件:
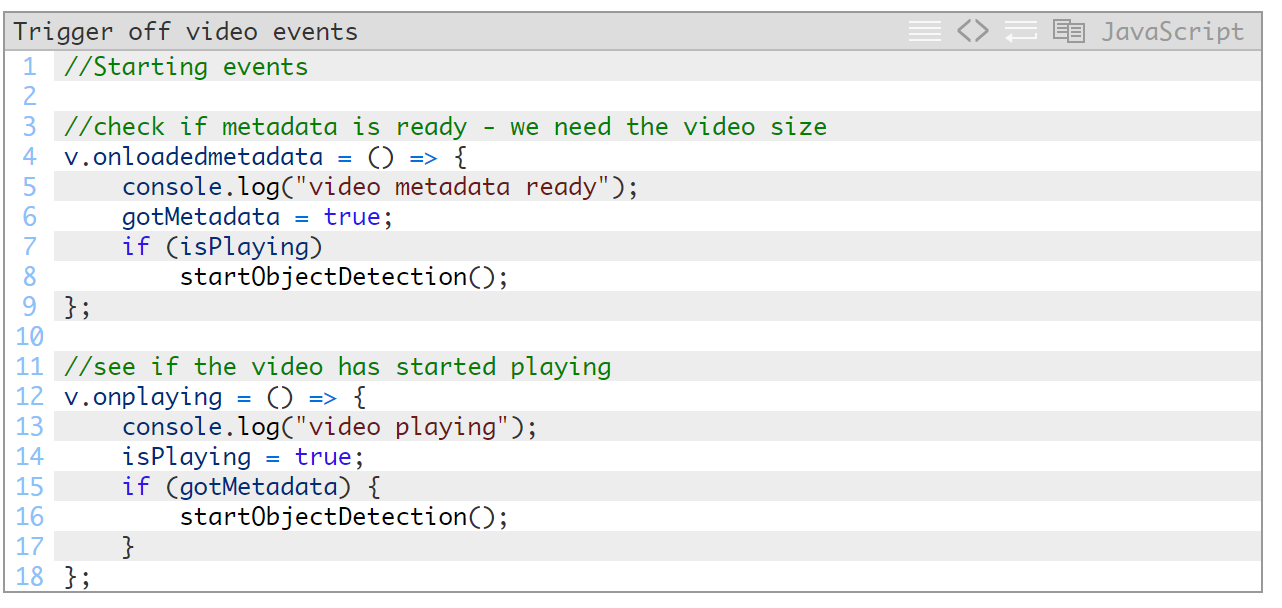
先查找视频的onplay事件和loadedmetadata事件——如果没有视频,图像处理也就无从谈起。我们需要用到元数据来设置我们的绘图画布尺寸,使其与下一部分中的视频尺寸相符。
启动主对象检测子例程
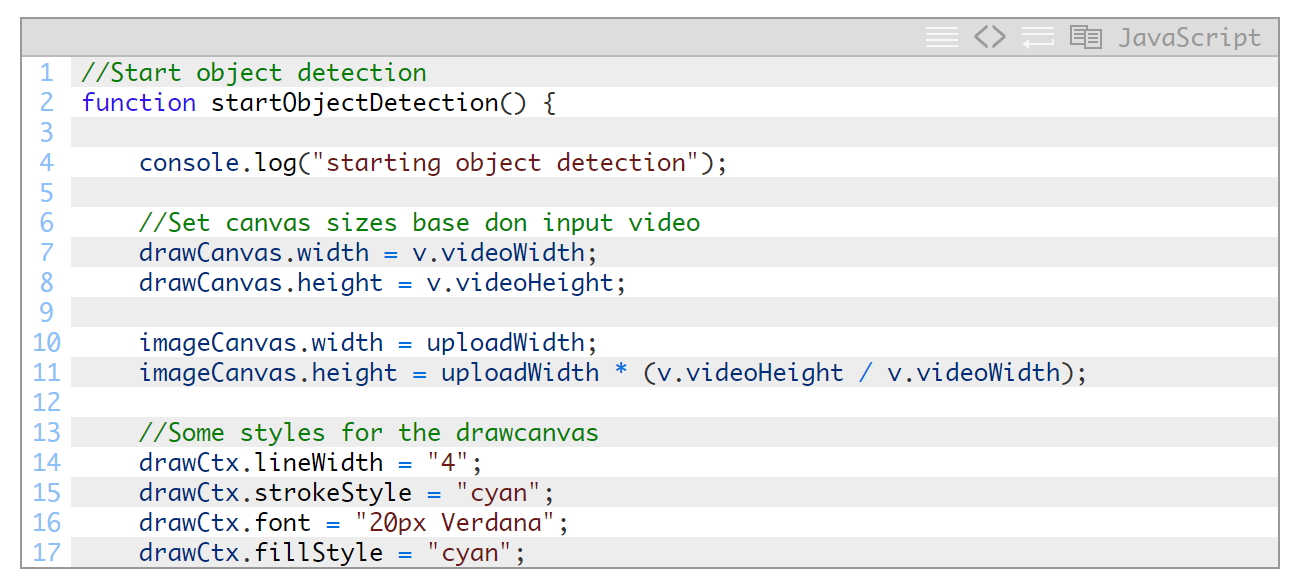
虽然drawCanvas必须与视频元素大小相同,但imageCanvas绝不会显示出来,只会发送到我们的API。可以使用文件开头的uploadWidth参数减小此大小,以帮助降低所需的带宽量和服务器上的处理需求。需要注意的是,减小图片可能会影响识别准确度,特别是图片缩减得过小的时候。
至此我们还需要为drawCanvas设置一些样式。我选择的是cyan,但您可以任选颜色。只是要确保所选的颜色与视频Feed对比明显,从而提供很好的可见度。
toBlob conversion

设置好画布大小后,我们需要确定如何发送图像。一开始我采取的是较为复杂的方法,结果看到Fippo的grab()函数在最后一个Kranky Geek WebRTC事件处,所以我又改用了简单的toBlob方法。待图片转换为blob(二进制大对象)后,我们就会将它发送到我们要创建的下一个函数,即postFile。
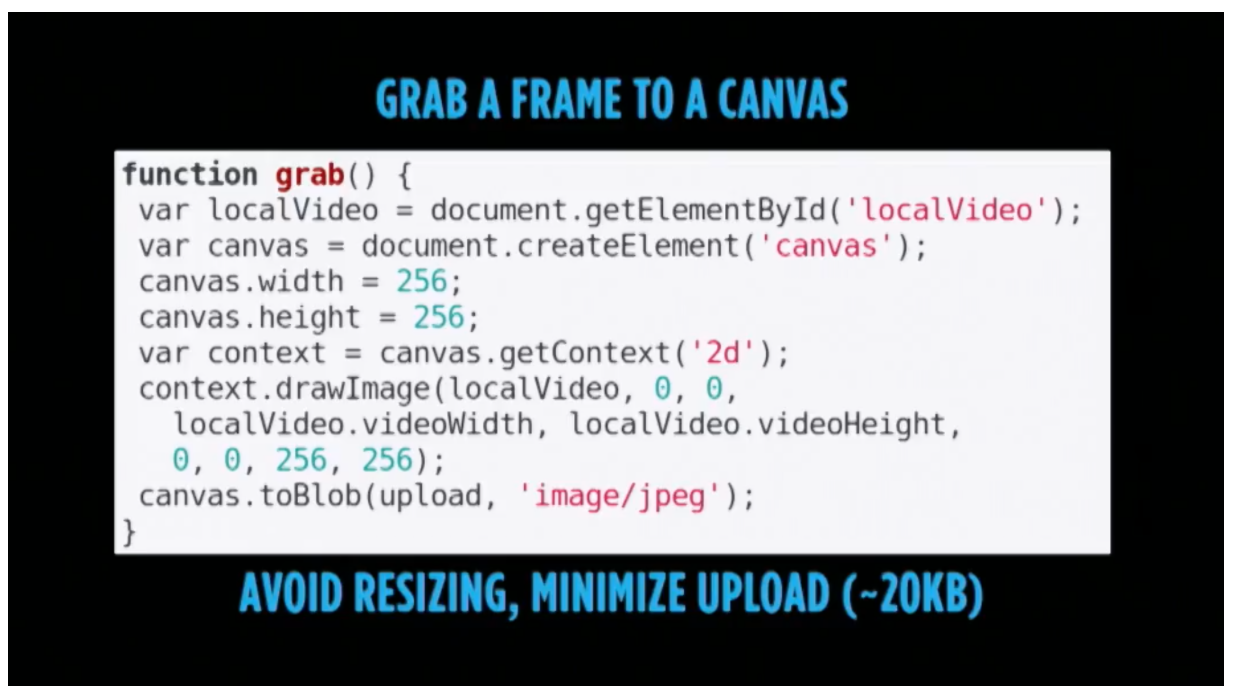

Philipp Hancke (Fippo)演示了如何从画布中抓取WebRTC视频帧并将它们上传到自己的Kranky Geek 2017。详情请观看NSFW——如何从实时视频流中过滤掉不良内容视频
有一点需要注意——Edge似乎不支持HTMLCanvasElement.toBlob方法。好像可以改用此处推荐的polyfill或改用msToBlob,但这两个我都还没有机会试过。
将图像发送至对象检测API
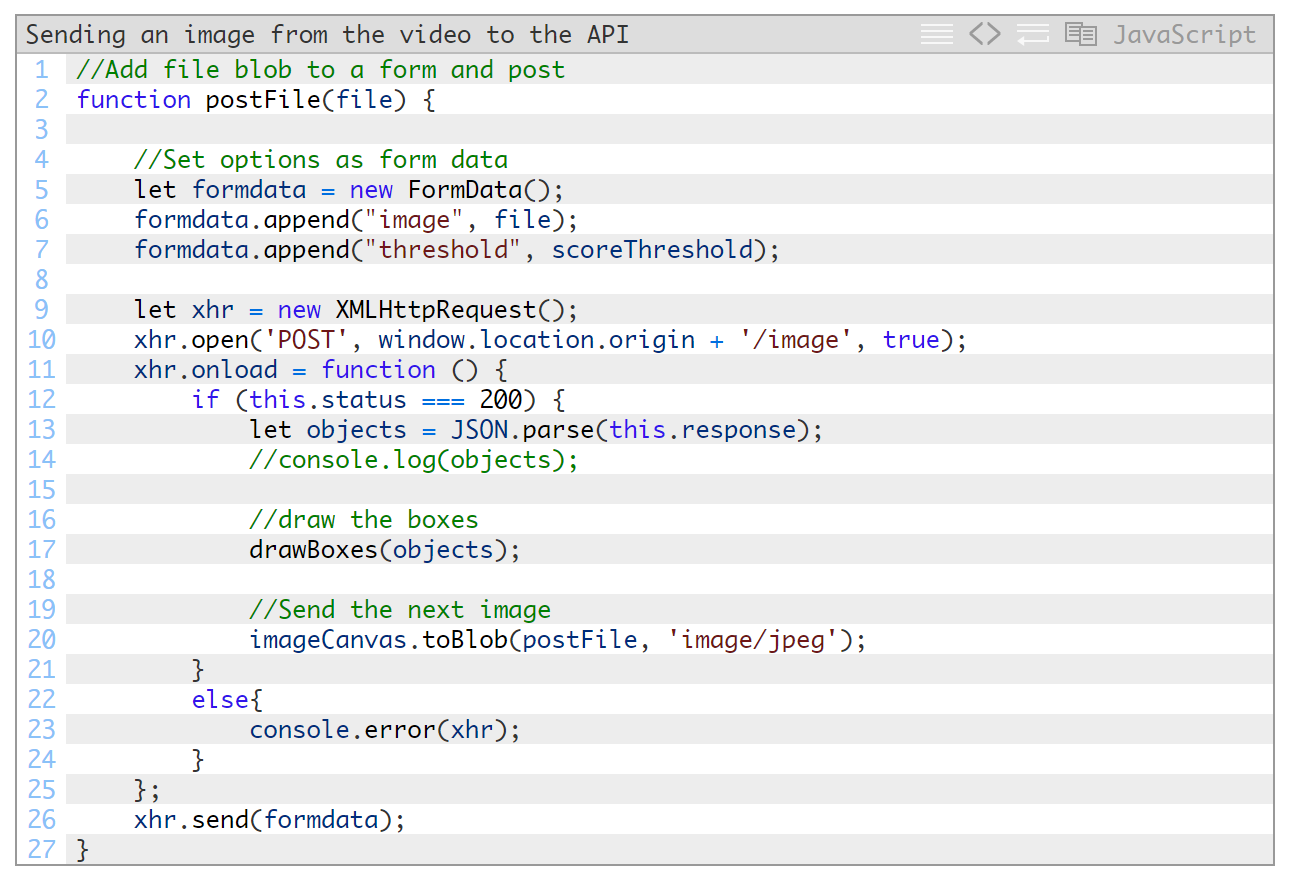
我们的postFile接受图像blob作为实参。要发送此数据,我们需要使用XHR将其作为表单数据通过POST方法发布。不要忘了,我们的对象检测API还接受一个可选的阈值,所以在这里我们也可以加入此阈值。为便于调整,同时避免操作此库,您可以在我们在开头设置的data-标记中加入此参数及其他一些参数。
我们设置好表单后,需要使用XHR来发送它并等待响应。获取到返回的对象后,我们就可以绘制它们(见下一个函数)。这样就大功告成了。由于我们想要持续不断地执行上述操作,因此我们需要在获取到上一API调用返回的响应后,立即继续抓取新图像并再次发送。
绘制方框和类标签
接下来我们需要使用一个函数来绘制对象API输出,以便我们可以实际查看一下检测到的是什么:
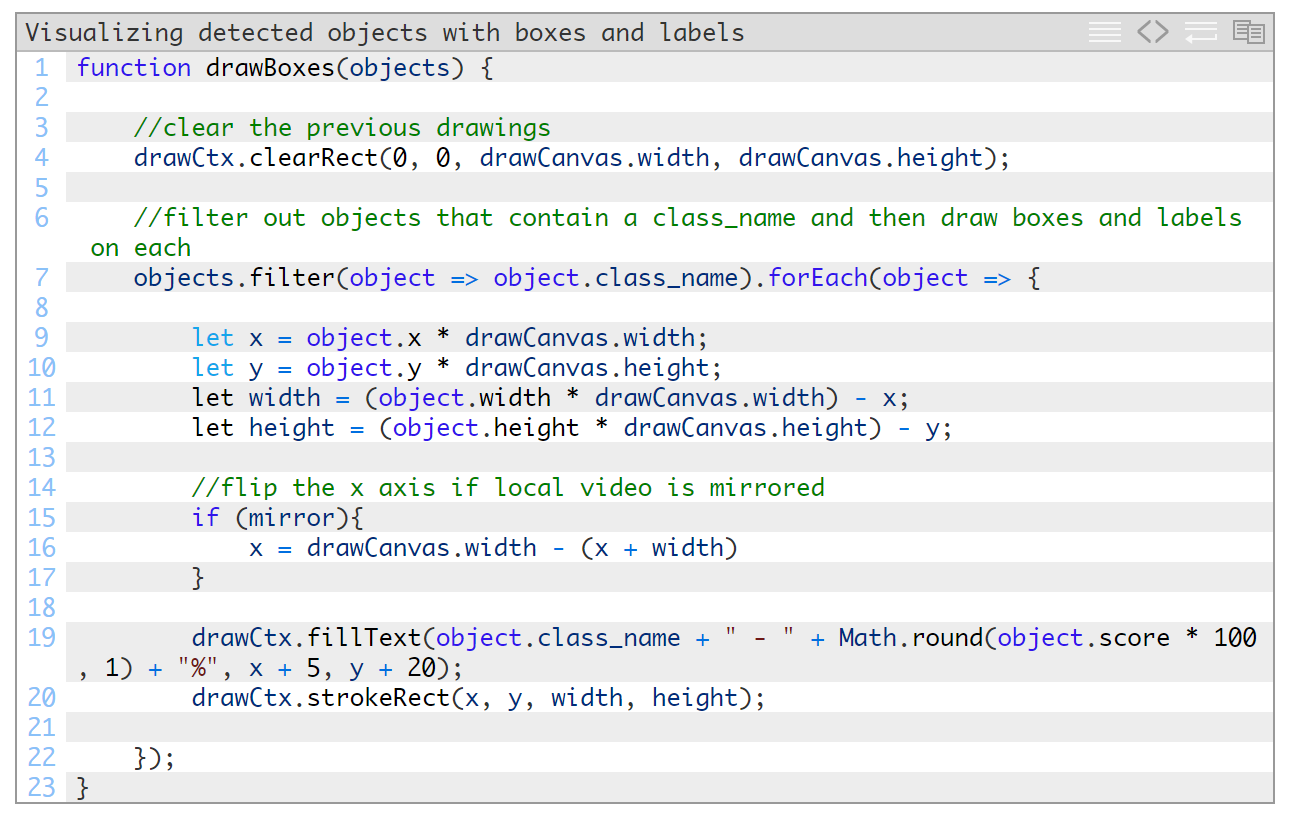
由于我们希望每次都使用一个干净的绘图板来绘制矩形,我们首先要使用clearRect来清空画布。然后,直接使用class_name对项目进行过滤,然后对剩余的每个项目执行绘图操作。
在objects对象中传递的坐标是以百分比为单位表示的图像大小。要在画布上使用它们,我们需要将它们转换成以像素数表示的尺寸。我们还要检查是否启用了镜像参数。如果已启用,我们需要翻转x轴,以便与视频流翻转后的镜像视图相匹配。最后,我们需要编写对象class_name并绘制矩形。
不妨一试!
现在,打开您最喜欢的WebRTC浏览器,在地址栏中输入网址。如果您是在同一台计算机上运行,网址将为http://localhost:5000/local(如果设置了证书,则为https://localhost:5000/local)。
优化
上述设置将通过服务器运行尽可能多的帧。除非为Tensorflow设置了GPU优化,否则这会消耗大量的CPU资源(例如,我自己的情况是消耗了一整个核心),即便不作任何改动也是如此。更高效的做法是,限制调用该API的频率,仅在视频流中有新活动时才调用该API。为此,我在一个新的objDetectOnMotion.js文件中对objDetect.js做了一些修改。
修改前后内容大致相同,我只不过添加了2个新函数。首先,不再是每次都抓取图像,而是使用一个新函数sendImageFromCanvas(),仅当图片在指定的帧率内发生了变化时,该函数才发送图片。帧率用一个新的updateInterval参数表示,限定了可以调用该API的最大间隔。为此,我们需要使用新的画布和上下文。
这段代码很简单:
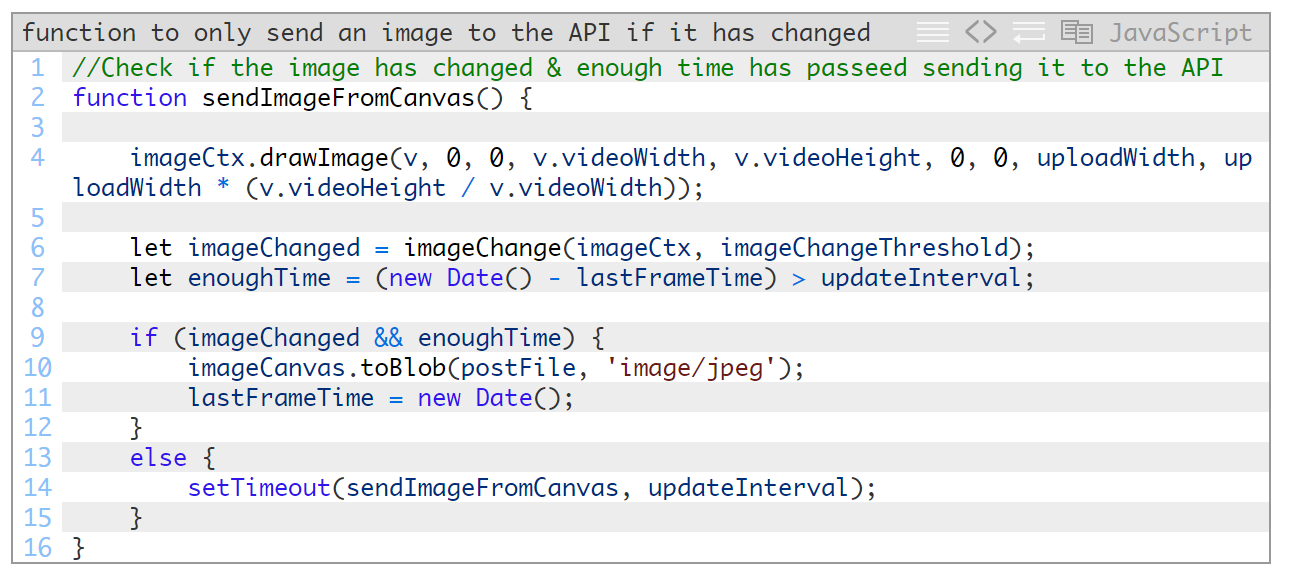

imageChangeThreshold是一个百分比,表示有改动的像素所占的百分比。我们获得此百分比后将其传递给imageChange函数,此函数返回True或False,表示是否超出了阈值。下面显示的就是这个函数:
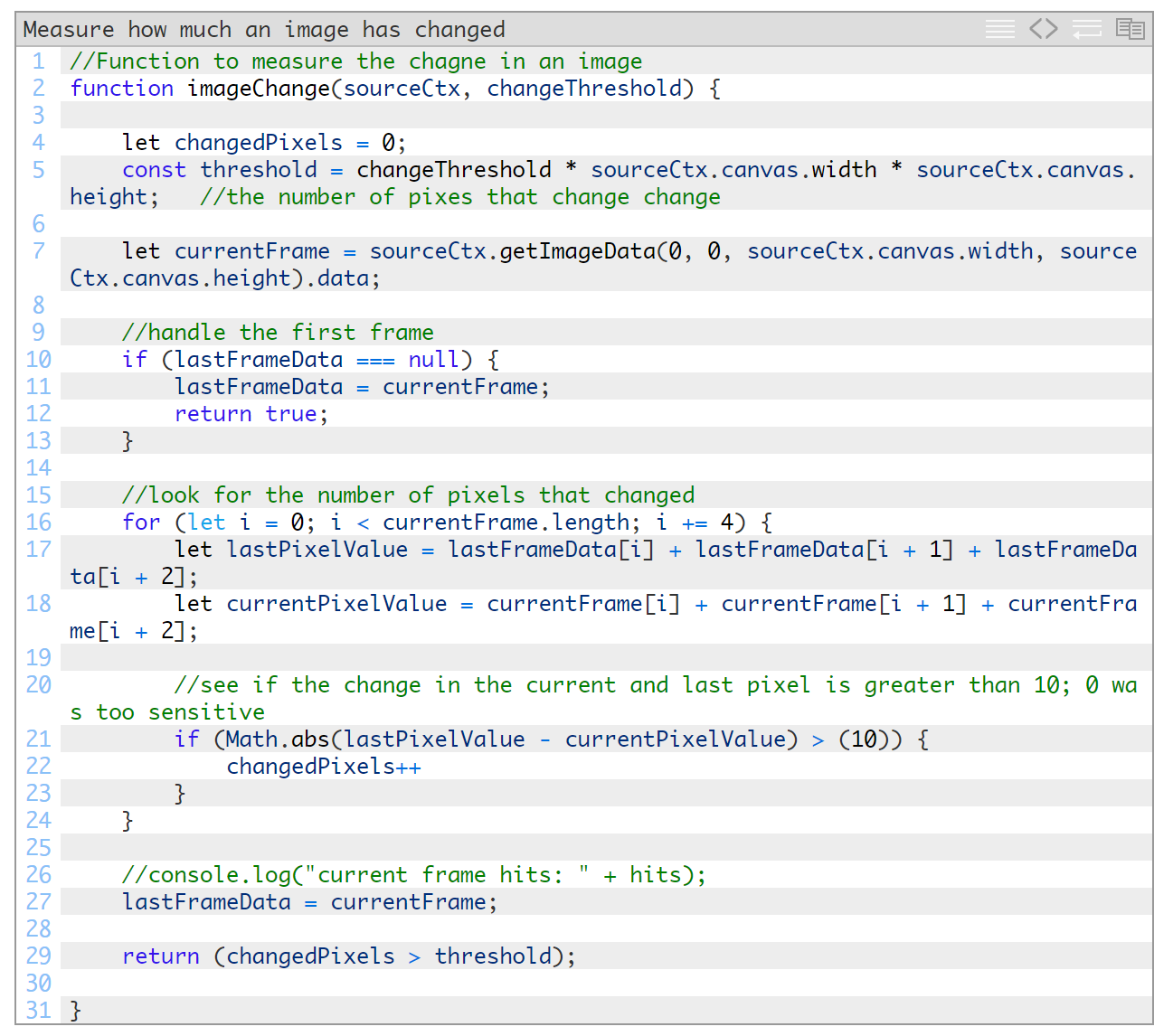
上面的这个函数其实是经过大幅改进后的版本,之前的版本是我很久以前编写的,用于在动作检测婴儿监视器程序中检测婴儿动作。它首先测量每个像素的RGB颜色值。如果这些值与该像素的总体颜色值相比绝对差值超过10,则将该像素视为已改动。10只是随意定的一个值,但在我的测试中似乎是很合适的值。如果有改动的像素数超出threshold,该函数就会返回True。
对此稍微深入研究后,我发现其他一些算法通常转换成灰度值,因为颜色并不能很好地反映动作。应用高斯模糊也可以消除编码差异。Fippo提出了一个很好的建议,即借鉴test.webrtc.org在检测视频活动时使用的结构相似性算法(见此处此处)。后续还会分享更多技巧。
适合任何视频元素
这段代码实际上对任何<video>元素都适用,包括使用WebRTC peerConnection连接的远程对等方的视频。我并不想把这篇博文/代码写得再长一些、复杂一些,不过我确实在静态文件夹中包含了一个video.html文件,作为演示之用:

您应该会看到下面的结果(在我从自己的如何利用JavaScript来训练狗狗项目中摘选的视频上运行):
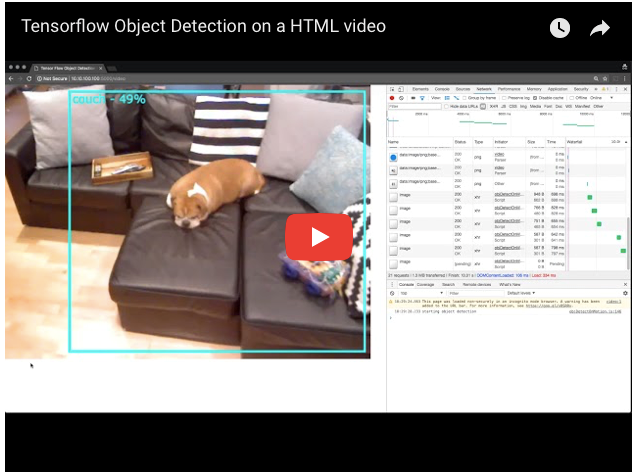
不妨使用您自己的视频试一下。只是提醒一下,如果您使用的是托管在另一台服务器上的视频,要注意CORS问题。
