在最开始,我们在产品方面做出了用户可以感受到的改变,这让你与朋友玩游戏时,Discord非常适合你们之间的语音交流。这些决定让我们在资源有限并且团队比较小的情况下扩大了经营。
本文简要介绍了Discord使用的不同技术,来让视频音频交流达到接近现实的效果。
为了区分,我们将会使用guild来代表一组用户和频道-在客户端它们被称为servers. Server被用来描述我们的后端架构。
Guilding 原则
Discord中所有音频视频交流都是多方的。支持大规模组内交流需要客户端-服务器的网络架构因为当参与者人数增多时,点对点网络变得非常昂贵。
通过Discord servers发送你所有的数据同样确保在输入文本,声音或视频时你的IP地址不会被泄露,这防止了其他人找到你的IP地址并且创建DDoS来攻击你。通过媒体服务器发送具有其它优势,例如对于使人讨厌的参与者,管理员可以选择禁止他的音频视频交流。
客户端架构
Discord在许多平台上运行:
1.网页 (Chrome/Firefox/Edge, etc.)
2.脱机app(Windows, MacOS, Linux)
3.手机(iOS/Android)
想要支持所有平台的方法只有让代码重复利用和WebRTC.WebRTC特指由网络,音频,视频等组件组成的实时交流,这些组件的标准由World Wide Web Consortium和Internet Engineering Task Force制定。WebRTC在现代浏览器中均可以使用并且可以作为一个library嵌入app中。
Discord的视频音频特性是由WebRTC实现的。这意味着我们的app依靠浏览器提供的对WebRTC的实现。然而,我们的桌面,iOS,和安卓App使用单一C++媒体引擎,它建立在WebRTC library的上层,并且被修改来迎合用户需求。这意味着某些特性在app中表现可能比在浏览器中表现更好。例如,在我们的原始app中我们可以:
1.避免Windows系统中默认交流设备会自动降低音量的行为。这意味着当交流设备使用时,windows会自动降低所有App的音量。如果你正在玩游戏并且在与队友使用Discord交流时,这种行为是不被接受的。
2.实现了自己的音量控制来避免改变操作系统的全局音量。
3.获取原始音频数据来进行声音检测,共享游戏音频和视频。
4.当安静时,降低带宽和CPU损耗—即使是少数几个人共同大声说话。
5.除了音频视频packets还会发送额外信息。
使用一个修改过后的版本的WebRTC意味着我们需要保持更新,这是一个麻烦的过程。然而向人们提供许多特性更值得。
在Discord里,声音视频交流从进入语音频道或通话开始。这意味着交流总是由客户端开始,这样就降低了客户端和后端的负担并且同样增加了对错误的快速反应。如果出现了结构错误,参与者可以直接重新连接到另外一个新的后端服务器上。
变为我们自己的
既然我们具有对原始library的掌控,我们在原始App中做了一些与你在浏览器的WebRTC实现中看到的不同的事情。
首先,WebRTC依靠SDP来在参与者之间交换音频视频信息。使用WebRTC原始library允许我们使用WebRTC的低版本API来创建发送流和接收流。当加入一个语音频道时,我们会交换最小数量的信息。这包括声音后端服务器地址和端口,加密方法和密钥,编解码器,和流的id.
webrtc::AudioSendStream* createAudioSendStream(
uint32_t ssrc,
uint8_t payloadType,
webrtc::Transport* transport,
rtc::scoped_refptr<webrtc::AudioEncoderFactory> audioEncoderFactory,
webrtc::Call* call)
{
webrtc::AudioSendStream::Config config{transport};
config.rtp.ssrc = ssrc;
config.rtp.extensions = {{"urn:ietf:params:rtp-hdrext:ssrc-audio-level", 1}};
config.encoder_factory = audioEncoderFactory;
const webrtc::SdpAudioFormat kOpusFormat = {"opus", 48000, 2};
config.send_codec_spec =
webrtc::AudioSendStream::Config::SendCodecSpec(payloadType, kOpusFormat);
webrtc::AudioSendStream* audioStream = call->CreateAudioSendStream(config);
audioStream->Start();
return audioStream;
}
更进一步,WebRTC使用ICE来确定参与者之间的最好的交流路径。因为每个客户端都通过服务器连接媒体,我们不需要ICE。这就允许当你在NAT后面时,我们提供一个更可靠的连接,并且对你的IP地址保密,不对频道中的其它参与者公开。客户端发送周期性的ping信息来确保防火墙一直保持开放状态。
最后,WebRTC使用SRTP来进行媒体加密。密钥是使用DTLS建立的,基于传输层安全协议,这在浏览器中每天都会用到。原始的WebRTC library允许你使用webrtc:Transport API来实现自己的传输层。
我们没有使用DTLS,SRTP,而是使用了更快的Salsa20加密。另外,在安静的时候,我们避免发送音频信息,这在小组规模比较大的时候经常发生。这导致了很多带宽和CPU。然而,客户端和服务器必须准备好接收音频信息并且重写音频视频packets序列号。
由于我们的浏览器APP使用了浏览器的WebRTC API, 我们使用了SDP/ICE/DTLS/SRTP.我们交换了客户端和服务器中所有必要的信息,并且SDP和客户端的信息综合起来。我们的语音后端架构负责桥接桌面和浏览器all的不同之处。
后端架构
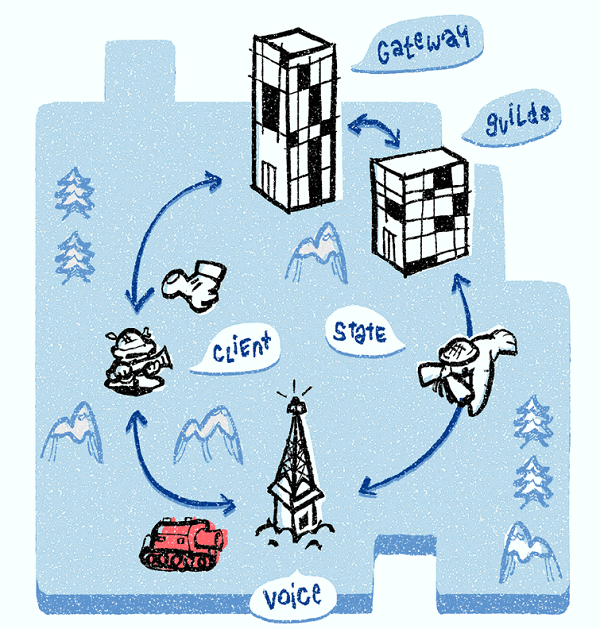
这里有多种后端服务,我们关注其中三种, Discord Gateway, Discord Guilds 和Discord Voice。我们所有的发信服务器都是用Elixir写的,允许了代码的重复利用。
当你在线时,客户端维持一个与Discord Gateway的WebSocket连接。你的客户端通过这个gateway连接接收事件,这个连接与guilds,频道,消息等等有关。
当你连接到语音频道时,连接状态由语音状态对象表示。客户端更新语音状态对象是使用gateway WebSocket连接实现的。
defmodule VoiceStates.VoiceState do
@type t :: %{
session_id: String.t(),
user_id: Number.t(),
channel_id: Number.t() | nil,
token: String.t() | nil,
mute: boolean,
deaf: boolean,
self_mute: boolean,
self_deaf: boolean,
self_video: boolean,
suppress: boolean
}
defstruct session_id: nil,
user_id: nil,
token: nil,
channel_id: nil,
mute: false,
deaf: false,
self_mute: false,
self_deaf: false,
self_video: false,
suppress: false
end
当你加入语音频道时,你被分配给一个Discord语音服务器。Discord语音服务器负责向频道传输每个成员的音频。Guild中的所有语音频道被分配到相同的Discord语音服务器上。如果你是Guild中的第一个语音参与者,Discord Guilds服务器负责使用如下方式向guild中分配一个Discord语音服务器。
分配一个语音服务器
每个语音服务器周期性的报告它们的状态和负载,这个信息被放入服务发现系统,就像上篇文章所讨论的那样。
Discord Guilds服务器查询服务发现系统并且向guild分配最少的可用的语音服务器。当一个Discord语音服务器被选择时,所有的语音状态对象都被放入语音服务器中。选中的Discord语音服务器同样会通知客户端。客户端打开第二个对语音服务器的WebSocket连接,它被用来设置媒体传播和说话暗示。
当一个客户端呈现等待断点时,这意味着Discord Guilds服务器正在寻找最好的Discord 语音服务器。当一个客户端呈现语音连接时,这意味着客户端成功的与选中的Discord语音服务器交换了UDP信息。
Discord语音服务器包括两个部分:一个发信部分和一个叫做SFU的媒体传播部分。发信部分完全控制SFU,并且负责产生流id和加密,传播说话暗示,等等。
本地的SFU负责在频道内传播音频或视频。我们的SFU被修改来迎合最大化表现和最低成本的需求。当使人讨厌的用户被mute之后,他们的语音packets就会被丢下。SFU同样起到了一个桥梁的作用,连接原始和浏览器App。它同时实现了脱机和浏览器App的传输和加密,并且在传输媒体packets时,两者之间可以进行转换。最终,SFU同样负责处理RTCP,来优化视频画质。它收集并且处理接受者的RTCP报告并且通知发送者对于视频还有多少可用的带宽。
失效备援
因为这是公共网络可以连接的唯一服务,我们需要对Discord语音服务器进行备份。
发信部分持续监控SFU。如果SFU崩溃,它会马上重启,来达到最少的服务中断。SFU的状态被通过发信部分重新建立,不需要任何客户端的交互。尽管SFU很少崩溃,但是我们使用同样的机制来进行零停机时间SFU更新。
当一个Discord语音服务器崩溃时,它就不会产生周期性的ping并且从服务发现系统中被移除。同样,客户端通过WebSocket连接注意到服务器瘫痪。Discord Guilds服务器确认崩溃,使用服务查询系统,给Guild分配一个新的Discord语音服务器。Discord Guilds接着更新所有的语音状态对象给新的语音服务器。每个客户端都被通知有新的语音服务器,并且向新的语音服务器来建立一个语音WebSocket连接来启动媒体。
Discord语音服务器遭遇DDoS攻击很普遍。我们使用同样的步骤,从服务查询系统中移除受影响的语音服务器,并给Guild选择一个新的Discord语音服务器,将所有的语音状态对象加入新的语音服务器中,并且通知客户端重连。当DDoS攻击减弱时候,服务器又被加入到服务发现系统中。
当guild拥有者决定选择新的语音区域时,我们同样使用上述操作。Discord Guilds服务器通过查询服务发现系统选择新的语音区域中可获得的最优的Discord语音服务器。将所有新的语音状态对象加入新的服务器中并且通知客户端。客户端断开之前的WebSocket连接并且向新的服务器建立WebSocket连接。
扩展
Discord Gateway, guilds, void都是水平扩展的。前两者是在Google cloud上运行的。
我们在13个区域中具有超过850个语音服务器。这就导致了处理数据中心崩溃和DDoS攻击的复杂度。我们最近新加入一个南非区域。多亏了我们客户端和服务器的架构,我们可以同时服务260万用户的会话。
原文标题:How Discord Handles Two and Half Million Concurrent Voice Users using WebRTC
作者:‘Jozsef Vass’
