部署WebRTC的媒体服务器有两个主要挑战,从一台服务器开始扩展,并且优化参加会议的用户的媒体延迟。尽管简单的碎片化方法像‘将X会议中的所有用户发送到服务器Y’容易实现水平扩展,在用户体验中,媒体延迟是一个关键因素,在这方面,此方法还远远不能达到最优效果。
将视频会议分布在距离用户很近的许多服务器上并且保持相互连接,同时解决了两个问题。来自Jitsi团队的Boris Grozev深度描述了级联SFU存在的问题并且展示了他们的解决方法和他们遇到的其它问题。
实时交流的App非常依赖网络环境,例如吞吐量,延迟,丢失。低比特率导致低视频质量,导致了视频音频中的传输延迟更高。丢包可以导致视频跳帧,进而导致‘波浪音’和视频冻结。
由于这些原因,在会议中,在两个端点之间选择最优路径是很重要的。当只有两个参与者时,这很直接—WebRTC使用ICE协议在两端建立连接,交换多媒体。如果可能的话,两端直接连接,不然的话,在少数情况下使用TURN传递服务器。WebRTC支持分解域名来获得TURN服务器地址,这使得选择基于DNS的本地TURN服务器相对简单,例如,使用AWS Route53的布线选项。
然而,当一个视频会议的参与者通过中心媒体服务器来发送时,情况变得更复杂。许多WebRTC服务像Hangouts,appear.in, Slack和我们自己的meet.jit.si,使用SFU来在参与者人数多于3人时更有效的传递音频视频。
星星拓扑存在的问题
在这种情况下,所有端都连接到了中心服务器,通过星星的拓扑结构,通过中心服务器来交换多媒体。很明显,选择服务器的位置对用户体验具有重大的影响,如果所有用户都在美国,使用在悉尼的服务器不是一个好的选择。
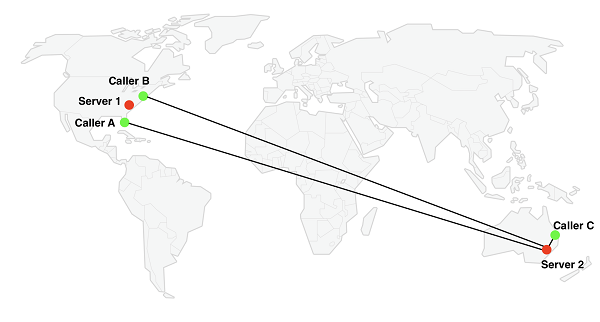
大多数服务使用简单的方法,大部分时间内表现良好:他们选择一台距离第一个会议参与者很近的服务器。然而,有些情况,这并不是最优的解决方案。假如有三个参与者如上图所示,两个在美国东海岸,第三个在澳大利亚,如果澳大利亚参与者首先加入了视频会议,这个算法选择一台在澳大利亚的服务器,但是在美国的服务器1号显然是一个更好的选择,因为它距离更多的参与者更近。
这种情况不常见,但是确实会发生。假设参与者加入的顺序是随机的,这就会在三分之一的三人视频会议中发生,其中一人在很远的地方。
另一种情况,更容易发生,如下图所示:存在两个不同地点的两组参与者。这种情况下,加入会议的顺序不重要,我们总是可以找到彼此接近的两个用户,但是他们的媒体需要经过一台遥远地点的服务器。例如,下图中,C和D代表澳大利亚参与者,A和B代表美国参与者。
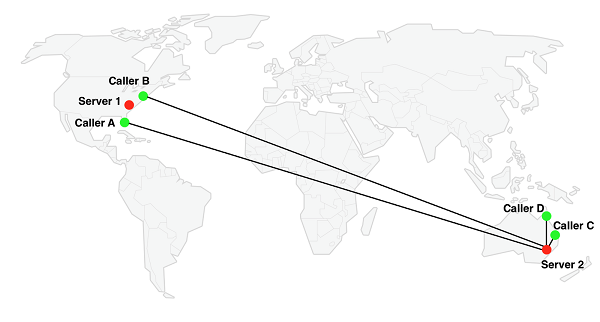
使用1号服务器对于C和D来说不是一个好的选择,同样使用2号服务器对于A和B来说不是好的选择。不管用1号还是2号服务器,都会用一些参与者要通过远程服务器来交流。
如果我们不止使用一台服务器呢?我们可以将每个参与者连接到本地服务器,我们只需要连接这些服务器。
解决方案:级联
之后在讨论如何实际连接服务器,首先我们看看这种做法的效果。
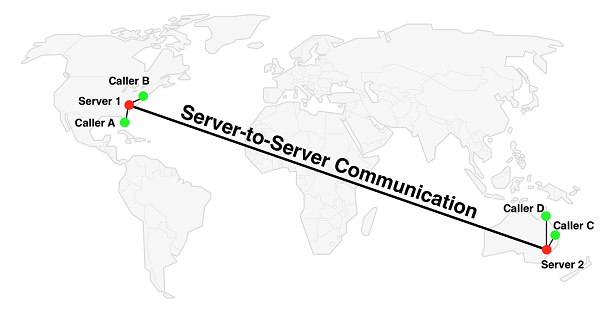
从C到D的SFU连接保持不变,还是通过2号服务器。对于A和B之间的连接我们使用1号服务器,显然看起来效果更好。增加的部分是连接A和C。我们使用A1号服务器2号服务器C这种连接方法。
不直观的传输时间影响
像这样连接SFU桥既有优点,也有缺点。一方面,我们的结果显示出这样的方法下,两端传送时间变长,由于我们增加了额外的跳转。但是另一方面,可以减少从客户端到第一个服务器的传输时间,这是它的优点,因为我们可以使用流修复来降低延迟。
它如何工作?WebRTC使用RTP,经常在UDP上,来传输媒体。这意味着传输并不可靠。当一个UDP包在网络中丢失后,取决于App,或者忽略,或者隐藏丢包情况,或者通过一个RTCP NACK包请求重新传输。例如,App可能会选择忽略丢失的音频包,部分情况下请求重新发送,但是不是对于全部的视频包(取决于是否需要对一系列的帧进行解码操作)。
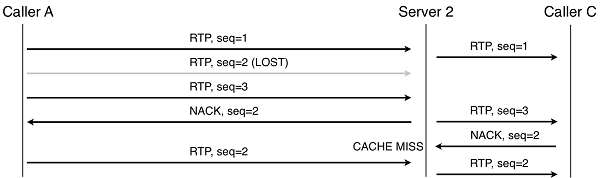
有了级联桥,这些重新传送请求可以被限制到本地服务器上。例如,在A-S1-S2-C路径下,如果在A和S1中出现丢包,S1会注意到,并且请求重新发送。如果S2和C之间出现丢包,C会请求重新传送,S2会从缓存中响应。如果两台服务器之间出现丢包,接收服务器可以请求重新发送。
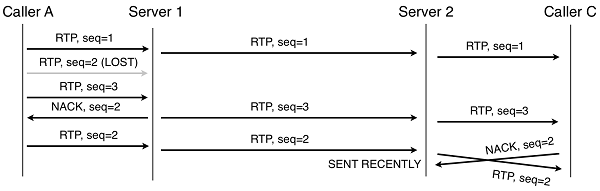
客户端使用jitter buffer,为了使延迟或者重新传输的信息到达。Buffer的大小根据传输时间动态变化。当重新传输一步步进行时,延迟较低,因此jitter buffer可以比较小,使得总体延迟更低。
总之,即使加入了额外的服务器之后,两端的传输时间变长,但是可以降低延迟。
实现级联SFU
我们如何在jitsi meet中实现它,如何部署到meet.jit.si上?
发信/媒体
首先考虑发信过程。起初,Jitsi Meet就将发信服务器(jicofo)和媒体服务器(jitsi-videobridge)的概念分开。这样使得实现对级联桥的支持相对容易。首先我们可以将所有发信逻辑统一到一起-Jifoco.另外,我们已经具有了处于Jicofo和Jitsi视频桥之间的发信协议。只需要添加一些扩展内容。我们已经实现了多个SFU连接到一个发信服务器的过程。现在需要添加一个SFU可以连接多个信令服务器的选择。
我们以两组服务器的结构实现,其中一组是jicofo服务器,另一组是jitsi-videobridge服务器。下图展示了具体结构。
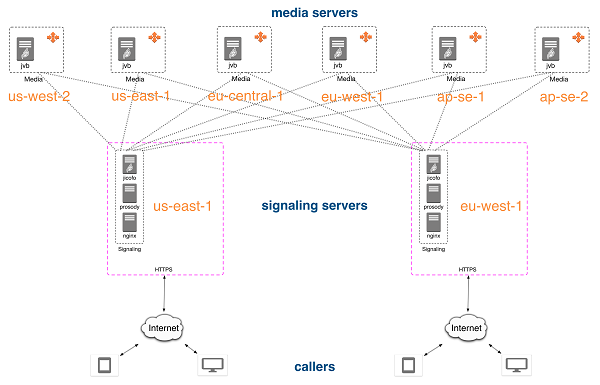
我们系统的第二部分是桥之间的连接。我们想使这部分尽量容易,因此决定在桥之间不进行任何显式发信。所有发信都发生在两个服务器之间,两桥之间的连接只用来接收客户端传来的视频音频和数据频道信息。
Octo协议
此协议使用固定长度的标题包裹RTP包,允许传输字符串信息。在当前实现中,桥之间是全网状连接的,但是这个设计也允许其它拓扑结构。例如,使用中心传输服务器(星状拓扑),或者树状结构。
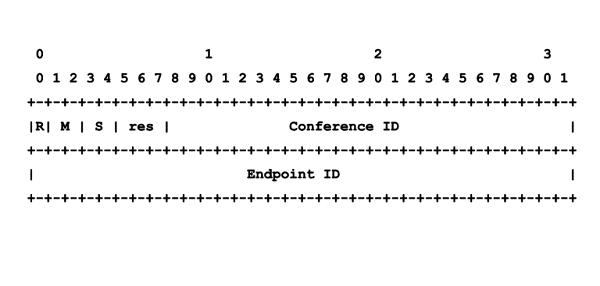
在Jitsi Videobridge中,当一个桥是多桥会议的一部分时,它具有额外的Octo频道(实际上,一个频道负责音频,另一个负责视频)。这个频道负责将媒体传输到其它桥,并且从其它桥接收信息。每个桥都被绑定到默认的4096端口,这就是为什么我们需要会议ID参数来迅速处理多人视频会议。
目前Octo协议不具备自己的安全机制,我们将安全机制委托到下一级。这是我们下一步要做的。
同时联播
Jitsi Meet的一个与众不同的特点就是同时联播,每个参与者发送多条不同比特率的流信息,桥负责选择接受所需的流。我们想确保它们可以正常工作,因此我们将所有同时联播流都传入桥中。这允许了流之间的快速切换,但是考虑到桥之间的网络拥堵,并不是最优选择,因为某些流不经常被使用,仅仅是消耗了额外的带宽,没有益处。
有源音箱选择
这很简单,只需要让每个桥各自对讲话的人进行id识别,通知本地客户端(其他人也在用这种方法)。这意味着需要多次计算,但是代价不算大,还可以简化某些步骤(这样就不必决定哪个桥进行DSI,和担心传输信息的问题)。
桥的选择
现在的实现方式中,选桥算法很简单。当新的参与者加入时,Jicofo需要决定分配哪个桥给他。它会基于客户端的位置和那个区域的可用桥的负载情况进行分析。如果存在一个可用的桥,Jicofo就会分配给参与者,否则,就会使用其中一个正在会议中被使用的桥。
关于设置Octo的细节,点击此处。
部署级联SFU
现在我们已经实现了地理上的级联,如上所述,在meet.jit.si上。
我们所有的机器都运行在亚马逊AWS上。我们在六个区域都有服务器(发信和媒体服务器):
1.us-east-1 (N. Virginia),
2.us-west-2 (Oregon),
3.eu-west-1 (Ireland),
4.eu-central-1 (Frankfurt),
5.ap-se-1 (Singapore) and
6.ap-se-2 (Sydney).
我们使用一层基于地理位置的HAProxy实例,帮助决定客户端所处区域。Meet.jit.si由Route53管理并分为HAProxy实例,它会将自己加入HTTP请求的标题中。标题用来设置config.deploymentInfo.userRegion变量的值。
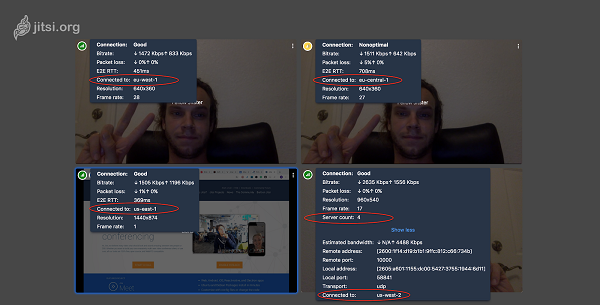
关于诊断和证明这个特性,用户界面会显示有多少桥正在使用,每个参与者连接情况。滑动界面,本地缩略图的左上角显示出服务器数量和你所连接服务器的区域。远程缩略图显示出远程参与者连接的服务器所处区域,和在两人浏览器之间的传输时间。
总结
在八月份,我们在meet.jit.si上安装了Octo,进行A/B测试。起初的结果看起来不错,现在每个人都可以使用。我们需要处理大量数据,计划详细查看Octo的工作情况,并发表更多有关文章。我们还计划使用这个结构作为以后支持大型视频会议(意味着需要更多SFU)的奠基石。接下来的几个月,请静静等待我们的研究结果。
原文标题:Improving Scale and Media Quality with Cascading SFUs
作者:‘Boris Grozev’
