新冠疫情使人与人之间的距离更加遥远。许多人转向在线视频会议来维系社交、教育和工作上的联系。如图所示,这种变化使得更多人使用Google Meet。
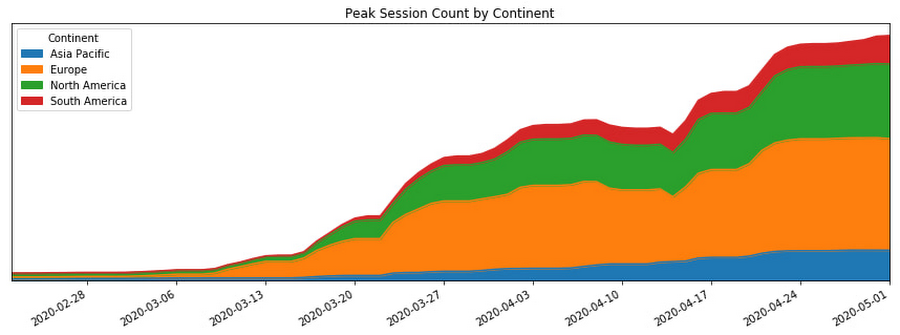
本文我会向大家介绍,我们是如何确保Meet的可用服务容量大于其疫情期间暴涨30倍的业务需求的,以及我们是如何通过利用大量网络可靠性工程(SRE)的最佳实践来实现技术和运营的可持续增长。
初期预警
随着新冠疫情席卷全球,人们开始适应疫情下的日常生活。新冠病毒对人们的工作、学习和与亲朋好友进行社交的方式的影响越来越大,这也意味着更多人使用Google Meet等服务来保持联系。2月17日,Meet SRE团队收到区域容量问题的页面。
这些页面的问题特点明显,或会产生黑匣子警报,例如“Too Many Task Failures”和“Too Much Load Being Shed”。由于Google面向用户的服务内置冗余性,这些警报并不能表明存在用户可见问题。但很快就有了答案——该产品在亚洲的使用人数正急剧上升。
SRE团队开始与容量规划团队合作,寻找更多资源来应对增长,但是我们确实有必要开始更进一步的规划,以防疫情蔓延到全世界,各区域使用人数激增。
果然,意大利此后不久就开始了封城,该国使用Meet的人数开始飙升。
突发情况
从那时起,我们开始制定应急方案。确实,宣布紧急状态,开始我们对该全球容量级别事件的应急响应,表明SRE团队着手解决这一问题了。
但值得注意的是,尽管我们使用传统应急管理框架来应对这一挑战,但那时Meet并不是已经或即将要崩溃了。不会对用户造成影响。新冠疫情对社会各方面的影响尚不清楚,很难预测。所以我们的任务很抽象——我们需要防止拥有大量新用户的黄金产品崩溃;同时要在不知道用户激增来自何处,以及何时疫情会稳定的情况下扩展系统。
最重要的是,由于疫情,整个团队(以及Google的其他成员)正适应着不确定何时会结束的远程工作。即使我们大多数工作流程和所需工具已经可以在办公室以外的地方访问,但线上运行这样一个长期应急事件仍然存在其他挑战。
由于无法与其他人一起在办公室里办公,主动管理沟通渠道以确保我们所有人都能获得实现目标所需的信息就变得很重要。我们中的许多人还面临着与工作以外的其他挑战。例如我们都要在适应过程的同时,照顾朋友和家人。尽管这些因素给我们的工作带来了额外的挑战,但诸如分配、增加备用数据库以及主动管理所有权和通信渠道等策略帮助我们克服了这些挑战。
目前,我们仍然在使用应急管理方法。通过在北美和欧洲设立应急指挥官、通讯负责人和运营负责人来开展我们的全球响应工作,以便我们能及时解决问题。
作为应急总指挥之一,我就像一个有状态的信息路由器一样履行职责,但我还可以发表意见、行使权力和进行决策。我负责收集状态信息。比如哪些关键问题亟待解决,谁负责解决这些问题以及问题会在哪些方面影响我们的响应(例如政府对疫情的响应措施)。然后我再把工作分派给相关的人员。研究“埋雷”区域(一是问题层面上,比如“以50%的CPU利用率运行南美服务器是否可行?”;二是解决方案层面上,比如:“我们要如何加快启动过程?”)后,我调整了整体响应工作,确保所有重要任务落实到个人。
响应工作开始后不久,我们就意识到涉及范围巨大,需要长期运作。为方便管理各工作人员的工作范围,我们把响应机制调整为多个半独立的工作流。如果各工作流范围有重叠,那就说明流之间的接口已经界定好了。过去那些案例中重叠的各工作流,其接口都已经界定好了。

以下是上图工作流的各部分说明。
- Capacity,负责寻找资源,确定我们可以在哪些地方,提供多少容量的服务。
- Dependencies,和安装了Meet基础架构(例如Google帐户验证和授权系统)的团队合作,以确保他们在用户增长过程中有足够资源去扩展。
- Bottlenecks,负责确定和消除系统中的相关扩展限制。
- Control knobs,在容量即将或已经崩溃时,把新的通用缓解措施内置到系统中去。
- Production changes,使用重新优化过的调试器来安全利用所有已发现的容量,重新部署服务器,并使用其他可用的Control knobs推动新版本发布。
作为应急响应者,我们反复评估当前的运营结构是否有效。我们想要的是一个有效运作所需的结构,仅此而已。如果架构太少,大家会在信息有误的情况下做决定,但如果架构太大,大家又会把时间浪费在计划会议上。
这是一次马拉松式的应急响应,不像短跑短时间内能解决。这整个过程中,我们会定期检查是否有人需要帮助或需要休息。这样能防止疲劳作业。
为防止疲劳作业,应急响应工作中的每个人都可以指定另一个人为自己的“后援”。该后援会和指定者参加相同的会议;他可以访问所有相关文档、邮件列表和聊天室;如果他们在现有相关储备不足就接手制定者工作时,也可以就相关问题进行提问。如果我们任何一位员工生病或需要休息时,“后援”便会派上用场,该候补人员已经拿到其所需信息,可以马上接手了。
建立容量库
在应急响应团队负责研究如何能完美协调解决应急情况所需的信息流和工作时,其中的大多数相关人员实际是在解决生产中的风险。
我们对技术的主要要求就是使Meet服务的区域可用量大于用户需求量。Google在全球有20多个数据中心,我们可以利用此强大的基础架构。所以我们马上使用了可用的原始资源,这足以使Meet的可用服务能力提高一倍左右。
以前,我们是根据历史趋势来确定需要提供多少容量。但由于我们现在不能再依赖于历史数据的推断,所以需要根据预测来配置容量。为了把上述那些模型转化为生产变更团队在生产时所能采取措施的基础,容量工作流需要把使用模型转化为我们所需额外CPU和RAM的数量。建立此转换模型是为了将来能通过教会工具和自动化理解生产,来加快获得可用容量的过程。
但很快我们发现,仅将容量扩大一倍是不够的,所以我们开始计划如何应对从未想过的50倍业务增长。
减少资源需求
除了扩大容量,我们还在努力识别和消除服务堆栈中的低效率问题,大致可分为这几类:调整二进制标志、分配资源以及重写代码使其执行成本更低。
要使我们的服务器实例资源利用率更高,需要多方努力。换句话说,就是“在不牺牲用户体验度或系统可靠性的前提下,以最低的资源成本处理更多需求问题”。
我们内部自查的问题包括:
- 我们是否能用最少的服务器储存最多资源,以减少计算开销呢?
- 我们保留的RAM或CPU是否比所需的更多?是否可以将这些资源作他用?
- 在网络接入层,我们是否有足够的出口带宽来服务所有地区的视频流?
- 我们是否可以通过分配使用中的后端服务器数量,来减少给定服务器实例所需的内存和CPU数?
即便我们不断改进新服务器的形状和配置,这两项仍然需要重新评估。随着Meet用户数量增长,其使用特征(例如会议持续时间、会议参与者数量、参与者语音的方式)也发生了变化。
由于Meet服务需要越来越多原始资源,我们发现我们CPU周期的很大一部分都花在了过程上(例如保持与监视系统和负载均衡的连接),而不是处理请求上。
为了提高吞吐量或“每秒1CPU处理的请求数”,我们在CPU和RAM存储上增加了进程的资源规格。该操作也可叫做“增肥”任务。
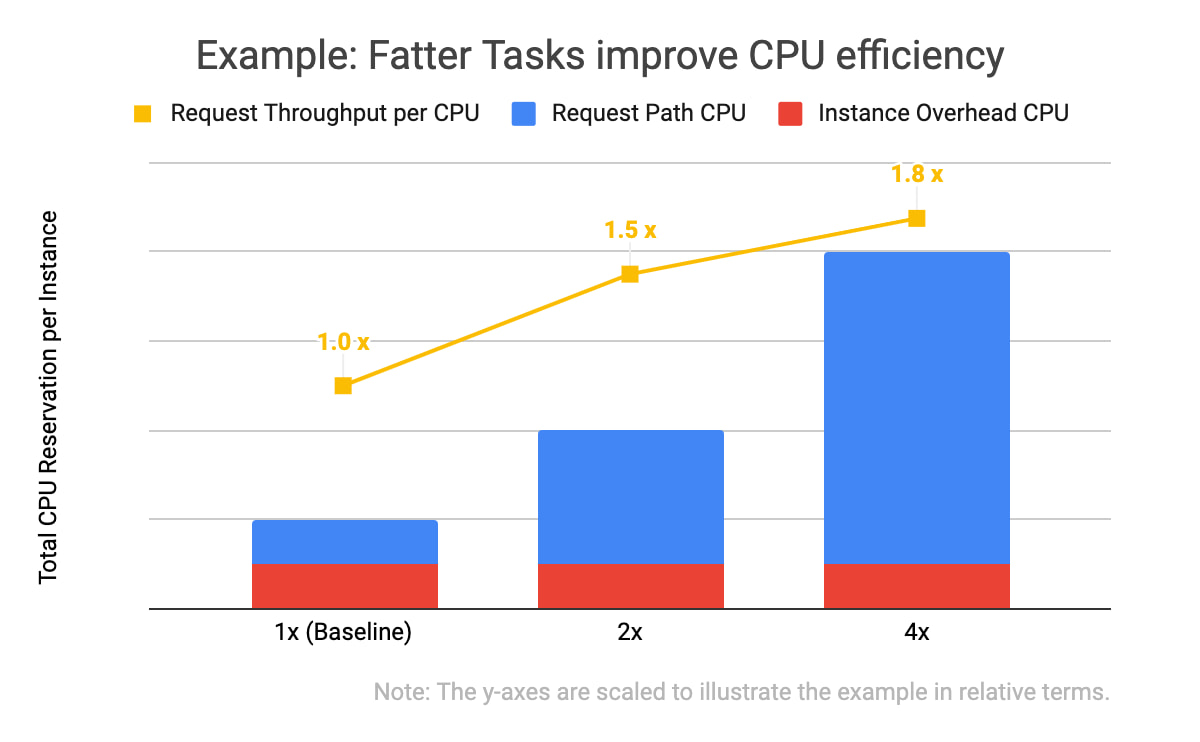
从上图的数据中,你可以发现两点:三个实例的规范计算成本(即红色块)相同,且实例的总体CPU预留越大,其请求吞吐量就越大(黄色块))。若分配的CPU总量相同,一个4x实例可以处理的请求数量为之前的1.8倍,相当于四个1x实例。因为计算成本(例如长期储存调试日志条目、检查网络连接通道是否仍存在以及初始化类)不会随任务正在处理的传入请求数量增加而线性式增加。
我们一直努力在扩展限制范围内把服务任务的预留量增加一倍,同时减少整个团队一半的任务量,
当然,我们会测试和验证每次更改。我们使用canary environments来确保这些更改符合预期,且不会引入或激发之前未发现的任何限制。该操作类似于我们对服务器新版本进行资格认证的方法,我们会确认该版本没有任何功能缺失或性能下降现象,且更改后的预期效果在生产中得以实现。
我们还对代码库进行了功能改进。例如,我们重写了内存中分布式缓存的代码,使其能更灵活分派任务实例中的条目。这使得我们增加一个群内服务器实例数量时,可以在一个区域中存储更多条目。
制定后备计划
虽然用户增长量应该与我们的预测相差不多,但毕竟不是完全一致。万一我们某个地区的服务容量不够怎么办?网络链接崩溃进不去怎么办?“控制钮”工作流可以提供令人满意的解决办法。我们要商讨出一个可行的计划来应对这些突发事件。
尽管我们希望不会有意外发生,团队中已经有一个小组在试图识别并建立更多的生产防控和后备计划了。比如有人加入Meet会议时,“控制钮”工作流能快速将视频默认的分辨率从高清降级为标准。这样,我们会有一定的富余时间用其他工作流(配置和提高效率)进行校正,同时不会造成产品的清晰度大幅下降。但只要用户愿意,他们仍然可以把视频质量调到高清。
如果我们的判断失误,那么像这样已完成构建、测试并准备就绪的控制工具就可以缓解我们的压力。
运营的可持续性
这种结构化应急计划需要大量不同职务的Google员工,才能得以实现。为了不断取得进展,我们需要进行严谨的协商和沟通。
我们每天都会开交接会议来欢迎两个不同时区里位于苏黎世、斯德哥尔摩、华盛顿州柯克兰和加利福尼亚桑尼维尔的Google员工们。这样的沟通为我们的产品团队、主管、基础架构团队和客户等利益各方提供了定期更新的支持操作,以便每个团队在做决定时都能获得最新的状态信息。“控制钮”工作流使用Google文档来更新共享文档,内容包括当前的风险、联络点,现行的的缓解措施以及会议记录。
该计划可以很好地维持我们的日常运转,但可能很快就负载过重。所以我们需要把计划周期从几天延长到几周,来有效减少协调所花费的时间,且增加我们实际用于缓解危机的时间。
因此,我们的首个策略是建立更好、更加可信的预测模型。提高可预测性意味着一整个星期,而不是一天的服务容量增长预测量,我们都可以稳定提供。
我们还要努力减少为提供额外用户容量所需的工作量。像我们的操作系统一样,我们的流程也要自动化。
以前,扩展Meet的服务堆栈是我们最耗时的工作,因为需要了解最新预测的人数、资源数量以及所需工具的数量巨大。

正如该生命周期图所述,通过逐步改进,我们才能使这些工作自动化。首先,我们把任务存档,然后开始自动化工作的各部,最后在理想情况下,该软件可以自动完成任务,无需人工干预。
为此,我们聘请了诸多来自Meet内部和外界的自动化专家来解决这个问题。工作内容包括:
- 使更多产品服务适应权威检入配置文件的更改;
- 增强通用工具以支持一些Meet特殊的系统要求(例如更高带宽和更低延迟网络的要求);
- 调整那些随着系统规模扩大变得越来越不稳定的回归检查
自动化并整理这些任务,大大减轻了在新集群中启用Meet或部署二进制新版本所需手动操作的负担,提高了产品性能。这次扩展结束之际,我们已经能够完全自动化每个区域、每段服务容量的占用空间,避免了数百种手动构造的命令行工具调用问题。这让大批工程师有时间和精力去解决一些更困难但很重要的问题。
在扩大运营规模时,我们可以通过电子邮件在站点之间“离线”切换,进一步减少了参会次数。现在战略确定下来了,发展的道路也更长了,我们进入了纯粹的战术执行阶段。
很快,我们关停了应急结构,开始运营余下的部分,方法同运行其他长期项目一样。
后续
到应急结束时,每天有超过1亿人用Meet参会。这么大的体量并非一蹴而就就能形成。在新冠疫情爆发前,Meet团队预设的应急测试比疫情时所需增加容量的长度或规模要小很多。所以我们不得不匆忙制定了很多应急计划。
一路走来困难重重。我们必须以不同于普通运营期的方式来解决风险。例如我们把新的服务器代码部署到canary环境中时,所花时间比正常情况下要少,因为其中包含一些性能修复程序,使我们在耗尽可用区域容量前得以喘息片刻。
在为期两个月的应急工作中,我们掌握的最关键技能之一就是:灵活对风险和收益进行分类、量化和定性。每天我们都会学习到有关疫情封城、新客户计划开始使用Meet以及可用生产能力的新信息。有时这些新信息会使我们前一天所有的努力都付之东流。
时间就是金钱,所以我们无法以相同的优先级或紧迫性来对待每个工作项目,但我们还是要努力避免预测模型所提及的风险。坐以待毙是不可能的,因此我们能做的就是尽可能多地扩展,使用已有数据来进行做出精确快速的决策。
上述所有成就之所以成为可能,得益于十几个团队中聪慧、乐于合作、全能的人才。因为这些职能部门(SRE、开发人员、产品经理、编程经理、网络工程师和后勤)共同努力,我们才实现了这一目标。
我们为后续工作做了万全准备——向拥有Google帐户的每个用户提供免费的Meet服务。通常,向消费者开放产品本身就是一个大胆的扩展举动。但是鉴于我们已经完成了如此大规模的扩展工作之后,我相信,我们已准备好迎接下一个挑战了。
原文作者:Samantha Schaevitz
