在测试或监控 WebRTC 应用时,网络抖动和往返时间哪个更重要呢?
如果你已经拥有了自己的 WebRTC 应用程序。用户借助该应用来沟通交流。那你如何知晓用户体验如何?服务器地址是否正确?你是否正确配置了路由?你是否需要在法兰克福添加一个新服务器?是否在澳大利亚增扩规模会更好?
要回答这些问题,我们需要检查应用的用户以及应用使用质量。其中,在检查WebRTC 质量时,你会遇到很多关于网络抖动、延迟和往返时间的术语。
那么,使用 WebRTC 跟踪和使用 WebRTC 关注哪一个更重要?是网络抖动?还是往返时间呢?
我认为两者都很重要。但不能完全下结论。
让我们试着拆分这两大块,以便理解。
网络 vs 端对端延迟
我们可以用不同方式查看这些指标,特别是延迟和往返时间。但首先要解决的问题是:我们到底要测量什么?

上图是一次 WebRTC 会话中,网络流量运作过程的简化版本。这其中没有服务器,也没有很多其他组件。沿途的每个组件都可能会增加延迟,甚至影响抖动。
图中整体可分为3个不同部分:
1. 获取、播放媒体的外围设备。包括屏幕、麦克风、摄像头、扬声器等。它们都会增加固有的延迟,其中有些设备的增量很大。比如蓝牙设备就因增加过多延迟而颇受诟病。(点名iOS 15)
2. WebRTC 处理。其本身是为减少延迟和抖动而设计构建的,但实际它也产生了这两个问题。我们自己运营的媒体服务器中的WebRTC尤其如此,而在我们无法控制的浏览器,以及用户用来访问我们服务的浏览器中也是如此。
3. 网络。(至少在本文中)我们试图衡量这一指标。
有一点需要说明:多数情况下,在大多数用例中,我们基本无法控制或了解所使用的外围设备。所以衡量它们带来的影响也很困难,而且这个动作在很多实际应用中不可能实现。因此外围设备不纳入我们的考虑范畴。
WebRTC 处理和网络通常捆绑在一起,基本上没有办法将它们分开。所以我们需要根据所见和经验,来确定问题是出自网络(即基础设施和 DevOps)还是WebRTC 处理(即软件bug和优化)。
网络抖动vs往返时间(或延迟)
对我来说,网络延迟和往返时间的不同,类似于天气和气候。天气反映了大气的短期状况,而气候则是某个地点一段时间内的平均情况。
同理可得,抖动反映了网络中数据包流的短期情况,或更准确的问题,而往返时间(或延迟)是数据包流经网络,在较长时段内从一个位置到另一个位置的平均时间。
网络抖动回答了网络有多不稳定的问题。
往返时间(或延迟)回答了网络中存在多少延迟的问题。
什么是“网络抖动”?
在 WebRTC 会话中,我们会连续发送数据包。大多数情况下,语音通话每 20 毫秒就会发送一个数据包。视频通话时,我们会发送数据包以达到每秒 30 帧,通常每帧有多个数据包。这意味着通话中每秒有数百个数据包。
假设网络没有丢包,那么我们预期在相同频率下,能收到相同数量的数据包。
接下来,我们分别从发送者和接收者的角度来看看 200 毫秒的音频跨度。下图是 10 个数据包的数据:
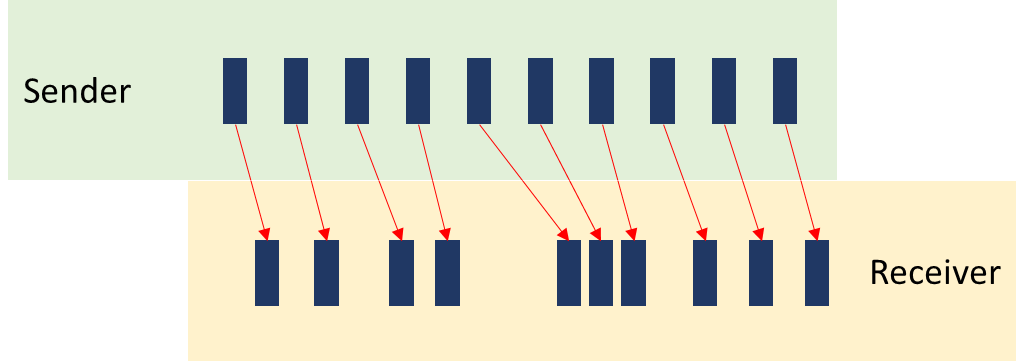
在上图中,发送方每 20 毫秒发送一个 SRTP 音频数据包,但接收方并不是每 20 毫秒接收一次。这说明过程中有点抖动。而这就是我们用网络抖动测量的情况。
什么导致网络抖动?
主要是网络。
当你通过互联网发送数据包时,怎么能保证所发送的数据能被及时接收呢?
就像邮局送信。并不是所有的信件最终都能到达目的地,也不是所有的信件都能按时到达。计算机网络也是如此,网络越复杂,就越难以正确完成这项工作。
以下是一些会严重影响网络抖动的因素:
- 用户的网络和位置。地理位置不佳。用户从电梯内部用流量连网,或者坐在离 WiFi 接入点很远的地方,都会导致阵发性连接,引起高抖动和数据包丢失。
- 网络拥挤。要么是本地问题(比如你的女儿在刷抖音,你的儿子在玩游戏,而你正试图通过 WebRTC 进行通话; 或者办公室里人太多,网速太慢; 或者体育场里有5万人同时在Facebook直播) ,要么是 WebRTC的基建因为流量堵塞了。
- 硬件故障。比如网线坏了。前段时间,我们有一个客户对其服务进行压力测试,结果发现数据包丢失(和抖动)都是因为他数据中心的一条网线坏了。
- CPU。用户设备或TURN的本地资源,以及媒体服务器本身都会增加抖动。如果机器的 CPU 开始节流,最终会导致抖动(和丢包)。
除了抖动之外,最终导致抖动的还有数据包丢失(指我们没有收到发送的数据包)、数据包重复(可能会发生这种情况)和数据包重新排序(如果数据包顺序出错,肯定会出现抖动,只是除此之外还会有别的问题)。
为什么网络抖动是个麻烦?
为什么是个麻烦?因为如果我们想要顺利地重新播放正在发送的音视频,我们需要使其再次匹配发送者的意图。更准确地说,要匹配麦克风和摄像头在发送端捕捉到的东西。
如果我们没能匹配接入的媒体,音频听起来会很自然,视频会断断续续。如果你想亲自试一试,只要在视频通话时,让其他事项占用你所使用设备的 CPU就可以了。
WebRTC如何解决抖动问题?
所有 VoIP 服务都有这一功能——一个抖动缓冲区。抖动缓冲区是一个基于组件的软件工程,用于收集接收到的数据包,并决定何时发出它们。它用于处理唇音同步(同步播放音频视频),重新排序数据包,并考虑到网络上的抖动。
我们知道,抖动时间可能在30毫秒左右。那么抖动缓冲区应等待至少30毫秒后再回放数据包。这样做,无论何时我们需要流畅地回放数据包,那个数据包早已经被接收到了。
由于网络抖动本质上是动态的,所以WebRTC 的抖动缓冲区也是动态的。它是一个自适应抖动缓冲区,用于了解网络上有多少抖动,并根据网络显示的信息增加或减小缓冲区大小(也叫长度)。我们为什么要这么做?因为抖动太少意味着由于数据包丢失,或者不正确回放导致的糟糕用户体验;抖动太高意味着增加播放的延迟,这是我们不希望在实时交互式 WebRTC 会话中出现的。
我们要了解的是“延迟”还是“往返时间”?
延迟(latency/delay)、往返时间(round trip time)、RTT(往返时间的缩写)经常被放在一起讲。虽然他们之间有一些细微差别,意思也不尽相同,但只要它们越低,用户体验就越好,会话的互动性也就越强。
我通常是这样定义、分类这几项的:
latency是数据包从网络中的一端到另一端所需的时间。
往返时间(round trip time)是响应数据包返回所需的时间。
至于latency和delay,争论在于他们是否应该包括外围设备的内置延迟,甚至包括 WebRTC 处理在网络中的终端单元中,或服务器中所增加的延迟。
往返时间(round trip time)的争论在于处理传入信息,然后向其发送回复的处理时间(如果处理不正确,这本身就会增加相当大的延迟)。
那么,如何准确地测量延迟呢?如果两个设备上的时间不完全同步,我们又该如何测量呢?其实在大多数情况下,WebRTC 没有什么不同,应该注意的是往返时间。也就是说,如果我发送了消息并等待响应,我所要做的就是检查所要花费的时间。而这正是我们从 RTCP 报告和 WebRTC 统计数据中能收集到的信息。
什么因素导致了往返时间
首先是上文提到的影响抖动的因素。其次,网络数据包的路由同样也会导致往返时间。
要让我解释的话,我们可以假设TURN服务器、媒体服务器或网关位于“美国东海岸”。我们通常都会给自己第一个云数据中心取这个名字。
为什么呢?因为我们想建立全球性的服务,但首先要在美国站稳脚跟,所以这个数据中心需要建在美国。其次,地图显示东海岸是去到欧洲的最佳选择。因此,我们最终选择了东海岸的云供应商。至少在我们进一步拓展和分配服务之前是这样做的。
那么,如果对话双方是两个同在巴黎的人,而会话是通过我们在美国的媒体服务器传输的,会发生什么呢?
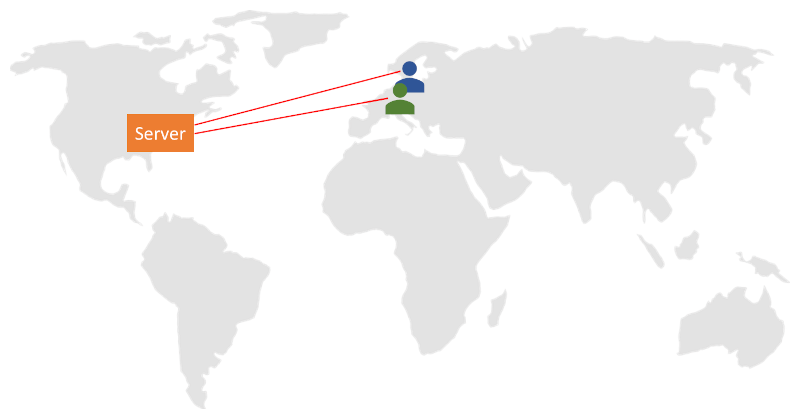
无论是从地理位置还是从时间上来看,这次对话都需要更长的路由,最终会增加会话的延迟时间。大多情况下,这意味着更高的丢包概率。因为沿途有更多的机会丢失数据包。
也就是说,我们设计基建、在全球各地部署和配置基建的方式,都对用户之后的往返时间体验有很大影响。
为什么往返时间过长是件坏事?
更多延迟意味着,从我们这一端到对方能够听到或看到效果需要很长时间。
对于实时流(某种程度上与 WebRTC 相关)来说 ,延迟的影响显而易见。
如果作用对象是监控摄像头,那延迟是很糟糕的。如果你处于一个交互式会话(比如一对一会话或者小组会议),延迟预期是低于200毫秒的。若超出这个范围,对话会变得奇怪,令人疑惑。你不知道其他人什么时候说完,自然你也无法在他发完言后参与谈话。
因此,为了在 WebRTC 应用程序中获得良好的交互体验,我们希望能做到低往返时间和低网络抖动。
WebRTC 如何解决高往返时间问题?
并没有解决。你需要决定将服务器放在何处,以及如何配置它们之间的路由以减少延迟。
最近我们看到的解决方案包括:
- 将更多媒体服务器和 TURN 服务器放置在更靠近用户所在位置的数据中心里
- 采用高密度分布式的第三方 TURN 服务器(比如Subspace和 Cloudflare)
- 采用类似 AWS Global Accelerator 这样的服务,可以优化路由。
在拓展业务时,你需要持续投入精力或者金钱,以便缩短往返时间。
丢包问题
我们需要注意:高往返时间或网络抖动很容易导致数据包丢失。
如果网络堵塞,可能会出现丢包现象。因为数据包路径上的网络交换或路由器会因为堵塞,丢弃一些数据包。
但是如果(因为往返时间太长或抖动太大)数据包到达的太晚,那么我们可能要放弃播放这一选择,因为时间点已经过去了。在这种情况下,即使数据包已被收到,WebRTC 也会直接丢弃数据包。WebRTC 的实时性决定了它不会永远都在缓冲数据。
网络抖动和往返时间——是基建问题还是终端用户问题?
两者都有。
有时,网络抖动和往返时间可能是因为基建出问题了——比如线路错误、网络配置不佳,或仅仅是系统太忙,无法快速处理数据。
其他时候,可能是用户的问题,有可能是因为他的设备不好,也可能是因为他正在使用的网络太差。
最后是网络。如果每个人都在同时尝试访问网络,那么肯定会有路线堵塞,只不过可能是偶发情况。
而你的工作就是努力了解问题的根源。
如何使用 testRTC工具修复网络抖动和往返时间?
Testrc 为 WebRTC 应用程序的整个生命周期服务。多数情况下,修复抖动和往返时间是你在终端上操作的一部分,你需要理解流量路由到哪里,以及如何将其重定向到其他地方(也可能需要添加新区域和服务器)。以下是我们解决网络抖动和往返时间的具体操作。
testingRTC
testRTC的 WebRTC 测试服务能帮助你进行集成、回归、功能、非功能、大小、负载操作,以及压力测试。
所有测试中,testRTC都会收集对话里模拟探测器的网络抖动和往返时间。testRTC把该测试服务当作黑匣子,从全球各地发布机器(由你定义使用哪些机器),再收集测试结果,使其成为testRTC存储的部分指标。该服务在通道级别、浏览器级别和测试级别上均可用,是一集合。通过仪表板和 api,你可以访问该服务,可以添加对这些值的预期数值,并通过设置阈值来控制测试是失败还是成功。你也可以动态更改测试中每个浏览器的这些值,并查看其对服务的影响。
upRTC
upRTC是WebRTC主动监控服务。其主要目的是理解基建的行为,并通过给用户端和网络带来可预测性来做到这一点。这样,你就可以确保监视器的浏览器每次在你的基建运行时,在网络端的行为都是一样的。
在该服务中,你可以查看网络抖动和往返时间,并设置这两项的阈值,通过电子邮件和 webhook接受提醒。
watchRTC
提供 WebRTC 被动监控。它能连接到用户设备,并收集用户的 WebRTC 指标,进而将其处理、整合和分析。我们收集和共享的部分指标是网络抖动和往返时间。且是在单个通道层面、端层面、聊天室层面,以及通过复杂过滤器进行整合的。
这样做的目的是:
让您了解终端用户的实时体验;
协助您跟踪设备类型、操作系统、网络、位置等方面的异常值;
当需要的时候,深入解决用户诉求
qualityRTC 及 probeRTC
通过qualityRTC和probeRTC,我们能解决你支持者和用户的这个问题,即如何改进与你服务的连接?
这是通过一系列测试完成的,其中许多测试收集网络抖动和往返时间数据。
文章地址:https://testrtc.com/network-jitter-or-round-trip-time-webrtc/
