很多人都试图实现一个酷炫新功能——背景分割。虚拟背景已经风靡一段时间了。我们所说的“分割”,不是在用户身后插入一个新的背景,而是完全移除他的真实背景,是允许视频软件把每个用户放进一个共享的屏幕里,或者说出现在一个共享环境中。这个功能还没有一个通用的名字。Zoom称之为沉浸式视图(Immersive View);微软称其为Together Mode。RingCentral称其为overlay。也有人叫它虚拟绿屏(Virtual green screens )或者新闻播报员模式(newscaster mode)
我想在浏览器中实现背景分割这一功能。不仅要把用户的自视图的背景变成透明的,也要让用户通过WebRTC对等连接,发送给其他人的视图背景分割。WebRTC确实使实现这一功能变得很容易。而像WebRTC Insertable Streams、Breakout box等新的API可以助力该功能更加高效。接下来我会介绍一些方法和发现。你也可以点击此处查看演示。
POC
首先,我会从代码POC开始,之后运用不同场景下的实验形成更全面的playground。你可以在https://github.com/webrtcHacks/transparent-virtual-background 上看到我的 repo。也可以在playground.html上自己进行操作(下面我会给出一个更简单的例子以供理解)。
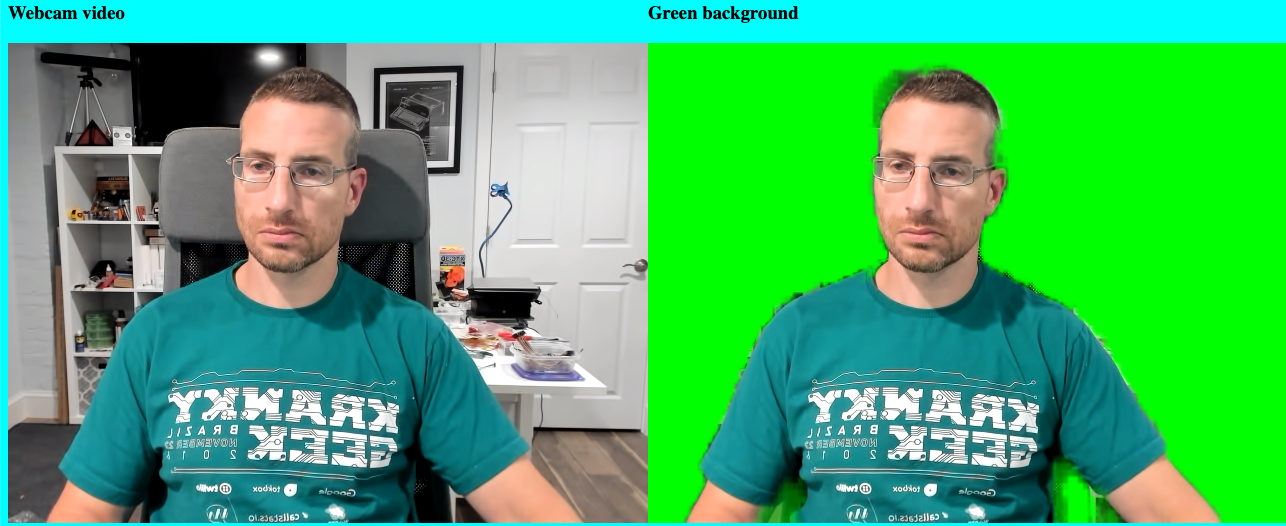
在本例中,我故意使背景难以辨认——我关掉了面前的灯,坐在高背椅上,穿着绿色Kranky Geek T恤,防止绿屏效应干扰。
切分背景
你要做的第一件事是将人像与背景分开。要实现这一点,你可以让用户自己设一个物理绿屏,或者使用机器学习库来实现目标。ML机制相对容易一点。疫情刚开始时,我就在Stop touching your face using a browser and TensorFlow.js.这篇文章中分享了如何使用tensorflow.js BodyPix库。该库主要用于人像各部分的分割,但也可以用它来分割人像和背景,它甚至有一个内置的Bokeh效果选项(即模糊背景)。MediaPipe建立在TensorFlow基础上,速度更快。Fippo在Making Zoom’s Smart Gallery on the Web with MediaPipe and BreakoutBox这篇文章中分享了MediaPipe的使用方法。
MediaPipe有一个Selfie Segmentation库,直接使用即可。如下:
const selfieSegmentation = new SelfieSegmentation({locateFile: (file) => {
return `https://cdn.jsdelivr.net/npm/@mediapipe/selfie_segmentation/${file}`;
}});
selfieSegmentation.setOptions({
modelSelection: 1,
});
selfieSegmentation.onResults(greenScreen); // handle the results
selfieSegmentation.send({image: videoElement});
我们只需要运行结果,去掉背景。
背景分割
selfieSegmentation模型返回的是一个只有用户的蒙版,其他像素都是透明的(为突出显示,我把页面背景做成了绿色)。

我们可以使用HTML canvas技巧来添加绿色背景。有很多功能强大的canvas图像合成操作可以帮助我们添加背景(详见MDN关于这些操作的文章)。 source-in可以在任何无像素的地方绘制新的像素。让我们来试着这样操作,只在前景中显示用户。
const ctx = someCanvasElement.getContext(‘2d’) // setup a canvas context
ctx.clearRect(0, 0, width, height); // clear the image first
// Draw the mask
ctx.drawImage(results.segmentationMask, 0, 0, width, height);
// Add the original video back in (in image) , but only overwrite overlapping pixels.
ctx.globalCompositeOperation = 'source-in'; // composition magic
ctx.drawImage(results.image, 0, 0, width, height);
你应该会生成一个这样的图像:

在特定帧中,我们可以进一步改进分割,但这不是此次实验的重点。接下来让我们通过RTCPeerConnection发送图像信息。
通过WebRTC 端对端连接发送切分背景图像
大家可以通过我的代码来了解设置,和通过端对端连接发送这个图像的方法。其实我只是把传入的数据流添加到一个<video>元素中。视频看起来就是这样的了:

看到了吗?为什么图像的背景不是透明的呢?这是因为WebRTC编码器不处理alpha通道。只要编码器看到RGBA:(0,0,0,255),它就将其转换为RGBA(0,154,0,254)。其中,A代表alpha,这里面的0代表完全透明,255代表完全不透明。
我第二天又试了一下,发现背景变成了另外一种绿色——RGBA(74,255,20, 254)。

我不确定为什么一天之后颜色的值就不一样了,可能背景的绿色是设计好的(但这看起来有点像bug 762443)。无论如何,现在背景是绿色的了。接下来我们只需要让它变透明。
添加透明度
WebRTC不会发送透明度(具体进程见discuss-webrtc),但我们可以把它加回去。我发现最简单的方法就是把图像画到canvas上,然后逐个像素进行浏览,在所有有绿色的地方添加透明度。
绘制到canvas上:
const outputCtx = outputCanvas.getContext('2d');
const getImageData = () => {
outputCtx.drawImage(source, 0, 0, width, height);
const imageData = outputCtx.getImageData(0, 0, width, height);
const transparentImageData = addAlpha(imageData); // add transparency
outputCtx.putImageData(transparentImageData, 0, 0); // draw it
requestAnimationFrame(getImageData); // do it again
};
getImageData();
之后添加addAlpha函数进行逐个像素浏览:
function addAlpha(imageData, gFloor=105, rbCeiling=80) {
const {data} = imageData;
for (let r = 0, g = 1, b = 2, a = 3; a < data.length; r += 4, g += 4, b += 4, a += 4) {
if (data[r] <= rbCeiling && data[b] <= rbCeiling && data[g] >= gFloor)
data[a] = 0;
}
return imageData
}
如果你习惯于处理多维图像数组,那么canvas上的getImageData看起来就会很奇怪,好像只是一长串没有任何对象结构的原始比特。它遵循的是以下这样模式:

这个函数只用于在数据中移动,寻找没有红色或蓝色的地方,以及绿色大于某个底限值gFloor的地方。由于有时红色的r和蓝色的b值可能会被填满,我们还需要给这些值设一个上限。虽然大多数像素都是RGB(0,154,0, 254),但经过实验,我发现把gFloor设置为105左右,rbCeiling设置为80的总体效果最好。这样可以消除分割和WebRTC编码/解码过程中产生的任何伪影。

增强功能
在sender上添加一个虚拟绿屏
我用妻子的Macbook进行了快速测试,得到的结果如下。

在部分人像周围,绿色代替了透明背景,而其他地方是纯黑色的。编码器到底怎么了?!
端对端连接的编码器好像把视频流的阿尔法像素改成了不同的值,这让我很担心。(接下来,我要检查WebRTC编码器代码,看看它是如何运行的。) 一般来说,通过端对端连接发送的阿尔法通道图像最终会在分割线周围出现了一些绿色的光晕假象。在某一个初始原型中,我给源图像添加了一个绿色背景,并通过端对端连接发送。看起来这种方法更可靠。
实现该背景很简单,利用我们上述提到过的内容即可:
function greenScreen(results, ctx) {
ctx.clearRect(0, 0, width, height);
// Draw the mask
ctx.drawImage(results.segmentationMask, 0, 0, width, height);
// Fill green on everything but the mask
ctx.globalCompositeOperation = 'source-out';
ctx.fillStyle = '#00FF00';
ctx.fillRect(0, 0, width, height);
// Add the original video back in (in image) , but only overwrite missing pixels.
ctx.globalCompositeOperation = 'destination-atop';
ctx.drawImage(results.image, 0, 0, width, height);
}
使用WebGL精细化图像
在研究如何做到这一点时,我翻到了James Fisher的一组帖子,文中演示了他如何使用WebGL和OBS(Open Broadcast Studio)实现了抠除了除人像以外所有实体的绿屏。 (他还有一个更厉害的演示——不在场背景移除:通过比较你出现在摄像头里的画面和你不在摄像头里的画面,来移除你的背景)。
WebGL应该是很快能完成操作的。但是使用WebGL与使用HTML canvas的工作方式完全不同,看起来我要从头学习才行。幸运的是James同意让我在样例中使用他的代码。鉴于我现在并不了解其工作原理,直接复制/粘贴他的函数是最快的方法了。
与我粗糙的绿屏和红蓝边缘不同,他的WebGL实现包括调整相似度、平滑度和溢出的选项。这需要很精确的操作,但也让我在切分绿屏边缘时获得更好的效果。

用Insertable Streams(即Breakout Box)整合
我的playground样例比较适合做快速比较。如果是做真正的APP就需要更加精简的方法。WebRTC应用程序通常会显示自视图,且需要给显示的传入流添加分割度。此外,大多数WebRTC应用是围绕<video>元素设计的,并非canvas。因此,我想试着用MediaStream输入和输出,不再依赖画布写入。
我也计划使用WebRTC Insertable Streams。WebRTC Insertable Streams允许使用W3C Streams API,或API其中的一部分来转换和创建MediaStreams。Fippo在他的这篇帖子中也提到了这种技术。
一体化示例
因此,我创建了一个合并示例——transparency.html。该样例整体包含在一个文件中。它只会给发送方和接收方各显示一个分割的<video>元素。切分和分割度都转换成了使用Insertable Streams的MediaStreams。
生成发送方的流水线
作为发送方,我希望流水线可以是这样的:通过tee操作,把切分出来的流再分成2个流,然后进一步处理。

不幸的是,tee()好像还不能同MediaStreams协作。参见详细解释,以及这篇WebRTC工作组文档,内含一些有价值的讨论,并对tee进行了一些很好的讨论。我发现tee操作应该可以协作,但我找不到一个成功案例。
即使tee能起作用,它的实现方式也不是我想要的那种。在tee操作下,你想输出的每个流都需要一个生成器提供的控制器:
let [track] = stream.getVideoTracks();
const segmentGenerator = new MediaStreamTrackGenerator({kind: 'video'});
const processor = new MediaStreamTrackProcessor({track});
const segmentStream = new MediaStream([segmentGenerator]);
processor.readable.pipeThrough(new TransformStream({
transform: (frame, controller) => segment(frame, controller)
}))
.pipeTo(segmentGenerator.writable)
.catch(err=>console.error("green screen generator error", err));
通过分割运行Frame。我把这个图像写到一个OffscreenCanvas上。然后使用传输的控制器从canvas上enqueue处理后的帧,并将其添加到生成器的segmentStream中。
async function segment(frame, controller) {
// see the source for the full function code
await selfieSegmentation.onResults(async results => {
segmentCtx.clearRect(0, 0, width, height);
segmentCtx.drawImage(results.segmentationMask, 0, 0, width, height);
// Grab the transparent image
// segmentCtx.save();
// Add the original video back in only overwriting the masked pixels
segmentCtx.globalCompositeOperation = 'source-in';
segmentCtx.drawImage(results.image, 0, 0, width, height);
const selfieFrame = new VideoFrame(segmentCanvas);
controller.enqueue(selfieFrame);
frame.close();
});
await selfieSegmentation.send({image: segmentCanvas});
}
在分段函数中,我真正想要的是2个控制器。这样我就可以一次性完成分割度和绿屏操作,并同时enqueue两帧。我还没找到一个行之有效的方法,能创建一个能编码2个不同数据流的转换流(参见WG会议)。其实我可以做两条独立的流水线,一个用于自视图,一个用于发送器,但这将重复密集的切分过程。
接收者流水线
最后,我创建了以下流程:

我不得不添加一个addGreenScreen函数,40行代码,包括它自己的MediaStreamTrackProcessor、TransformStream和TransformStream。在切分后,在生成器中运行的流编码过程是下一个最重要的操作。
接收方流水线比较简单——处理器→变换器→生成器。

性能
该程序的性能怎么样呢?我主要从两个维度上来判断。
- 视觉切分。用户和背景切分的程度如何?伪影多不多?有多少伪影透出了背景,又有多少伪影切分出了人像的一部分?
- 处理器的使用。分割度的使用是否会耗尽用户端的处理能力,使他们无法处理其他事情?
为了进行以上测试,我增加了在不同分辨率下进行切分的选项。更高的分辨率提供更多bit来处理,所以这也是观察流水线运行效率的一种方法。
我把测试结果记录在这张表上供大家参考。以下分享的结果仅针对WebRTCInsertable Streams方法论,表里还有playground测量的数据。
视觉性能
这一块儿我没有(还没有)做大量测试。因为需要很多志愿者。但归根结底,除了调整绿屏参数,以及做一些更高级的过滤和光线包装技术以外,没什么可改进的地方了。除此之外,你还要从0开始,搭建和训练一个改进过的切分模型。要超越MediaPipe的免费模型,就需要更强的数据集和一些深入的ML专业知识。
FPS和处理器的使用
这一项较容易测量。我用mrdoob的stats.js创建一个每秒帧数(FPS)表,然后在浏览器任务管理器中核查CPU使用率。以下是来自我MacBook Pro 2018,2.9 GHz,搭载 6核英特尔酷睿i9芯片,使用罗技Brio 4K web摄像头,运行Google Canary(97.0.4687.0)的结果。即使在测试中运行相同的参数,这些数字还是会来回波动。所以我们要把它们当作一个方向性的指标。在不同的测试中,它们一般都在同一范围内。
FPS
我把源视频设置为30FPS。发送器端的流水线效率能跟上吗?当发送器处于活动状态时,接收器的情况如何呢?
结果如下。
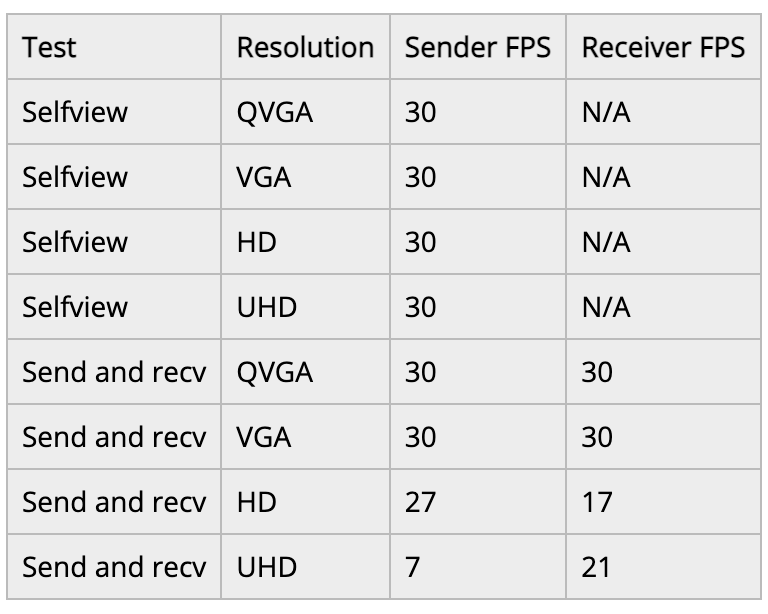
我,也就是发送方,用于自己端上显示的视频帧率,即便一直升高至 1920×1080 UHD,都没有出现问题。但接收方在升高到HD时开始出现问题(同时也显示高清的自视图)。升高到UHD时则完全无法使用。我检查了webrtc-internals,它显示的接收方帧率和发送方帧率相似——看来接收方背景消除 Pipeline效果较差。
CPU利用率
我在breakout box的例子中添加了一个选项,使其在没有任何切分或分割化的情况下运行,并作为一个比较基准存在。我只用一个标签运行,然后用Chrome任务管理器记录该标签的CPU、GPU进程和视频捕获进程。
仅仅是自视图的CPU占用率还行。但当使用了端对端连接后,额外的编解码处理在没有任何分割化的情况下,就增加了相当多的CPU占用。
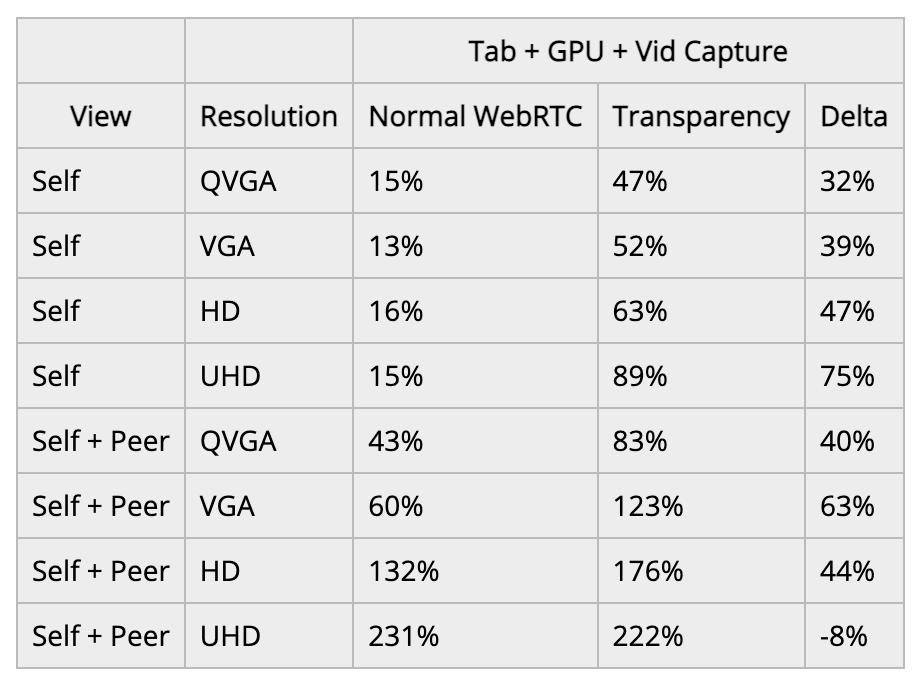
针对实际应用来说,VGA似乎是极限了。在VGA之后,CPU好像就开始节流了,把帧数降到了一个不可接受的水平。
挑战和计划
以上只是POC。接下来我想做这么几件事,其中一些是创建应用所必需的。
开发者
insertable streams的一大优势是,你可以在一个实际工作线程中处理,卸载你的主线程。这应该会加快你的操作进展。
使用带insertable streams的WebGL
我没有重写WebGL代码来处理insertable streams,所以它并没有出现在一体化示例中。
浏览器支持——仅限Chromium;可能有Firefox
现在我的样本只基于Chromium的浏览器。MediaPipe Selfie切分在Safari上运行时出现了一些问题。我的示例都使用了OffscreenCanvas,而Firefox和Safari不支持。所以我尝试将其切换为Firefox的onscreen隐藏canvas,但这样会增加工作量。Firefox和Safari都不支持用于insertable streams的MediaStreamTrack API,所以transparency.html的例子也无法进行实验。
最后,MediaPipe Selfie切分在Safari中不工作,所以除了修复上述问题外,还需要解决这个问题,才能获得更广泛的浏览器支持。
切分率
上述示例中,切分以每秒30帧的速度运行,以配合视频帧率。除非有大量快速运动,切分掩码才会每33毫秒改变一次(1帧/30帧=33毫秒)。只要用户位移不是过大,我们就可以通过减少改变来节省一些处理时间。但如果你把切分率设置得过低,那么切分蒙版将滞后于用户的移动速度。
在其他设备上测试
我很好奇这个测试在其他设备(包括移动网络)上的效果如何。我快速测试了一下,它起作用了,但帧率远远低于我的MacBook测试结果。
结论
有几家公司可以提供切分背景选项,所以这个操作绝对可行。使用MediaPipe等切分库和canvas操作实际上并不难。尽管源MediaPipe Selfie切分的切分能力很难提高,进一步的调整肯定还是可以提高其性能的。
文章地址:https://webrtchacks.com/how-to-make-virtual-backgrounds-transparent-in-webrtc/
原文作者:chad hart
