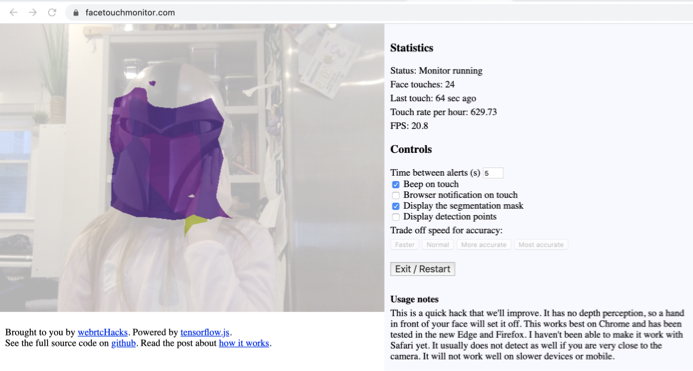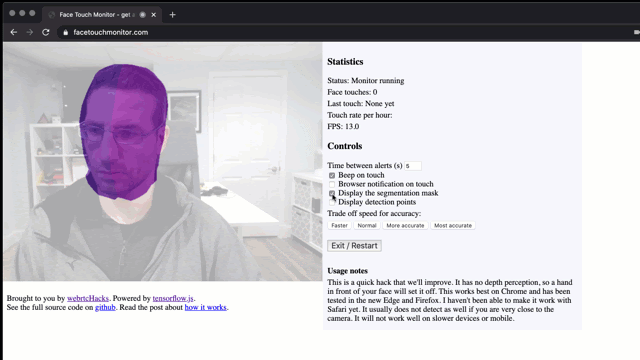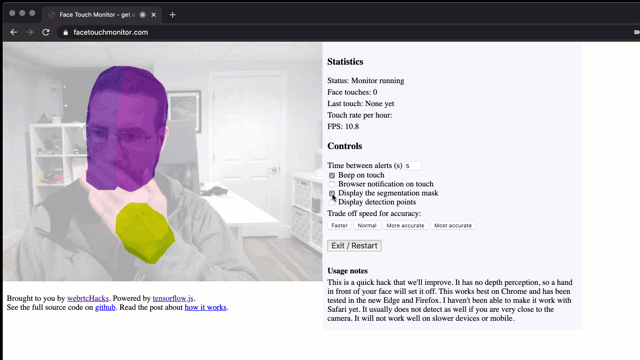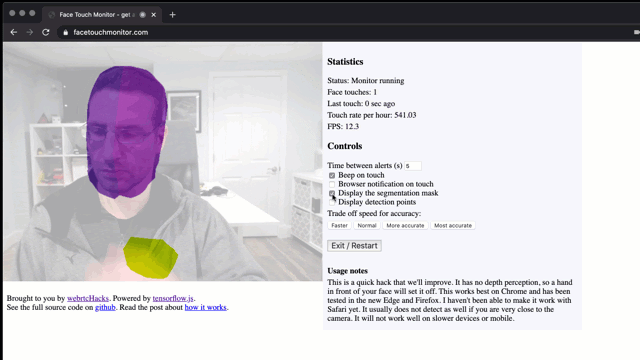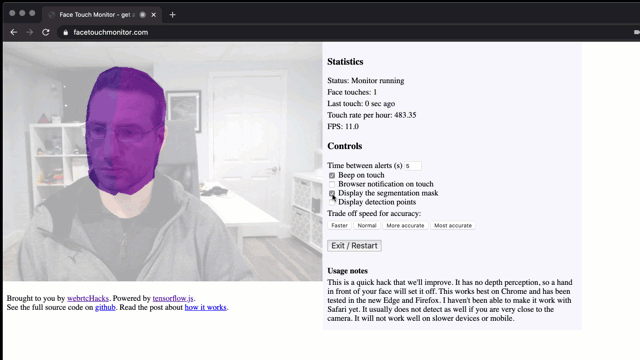
不要用手摸脸啦!为防止新冠状肺炎病毒疫情传播,医疗机构建议我们不要用没洗过的手摸脸。但如果您坐在计算机前几个小时不动,要做到这一点就很难了。我不禁想,用浏览器可以解决这个问题吗?
为此我们进行了许多计算机视觉和WebRTC实验。我早已计划去进行用TensorFlow.js在本地浏览器中运行计算机视觉的实验,现在似乎是个好机会。通过快速搜索,我发现有人在2周前已经想过这样做了。但是该站点使用的模型需要一些用户培训才能理解,这很有趣,但也可能有风险。并且它不是供其他人扩展的开源软件。因此在周末,我通过编码隔离做了一些处理,看看结果如何。
你可以在facetouchmonitor.com上查看该程序。 也可以继续阅读下面的内容以了解其工作原理。所有代码都可以在github.com/webrtchacks/facetouchmonitor上找到。我会在本文中分享一些要点和备选方案。
TensorFlow.js
TensorFlow.js是Tensorflow的JavaScript版本。您可能听说过Tensorflow,因为它是世界上最受欢迎的机器学习工具。 TensorFlow.js充分吸取了机器学习的优点,并将应用于支持JavaScript 的node.js和浏览器中。更好的是,TensorFlow.js中包含几个主要的TensorFlow模型库中用于计算机视觉的预构建模型。本文会介绍其中两个模型。
TensorFlow.js + WebRTC
Tensorflow对WebRTC非常友好。其基本模型适用于静态图像,但TensorFlow.js包含帮助程序功能,可自动从视频供稿中提取图像。像tf.data.webcam(webcamElement)等某些功能,甚至可以为您调用getUserMedia。
使用KNN分类器进行转移学习
donottouchyourface.com在几周前发布,也收到了一些好评。初次使用时,您需要使其熟悉你的面部轮廓,大约5秒钟就可以了。然后您需要触摸脸部,多次重复此过程。该程序会播放一个音频文件并发送浏览器通知。如果之后您的位置与识别过程中的位置相同,那么程序会成功运行。但是如果您在识别过程中改变位置,或没有提供足够的可识别项,程序运行可能会很不稳定。示例如下:
工作原理
即使结果不那么准确,在浏览器中执行此操作仍然很炫酷。那么开发者是如何做到的呢? 从他们的JavaScript会发现,他们使用了obilenet和knnClassifier库:
import * as mobilenet from '@tensorflow-models/mobilenet'; import * as knnClassifier from '@tensorflow-models/knn-classifier';
MobileNet模型似乎被用作基础图像识别库。在识别过程中,它会从摄像机中获取一系列图像,并将它们分配到“触摸”、“不触摸”中的一项内。然后用KNN分类器进行转移学习,对MobileNet进行再识别,最后根据这两项对新图像进行分类。
实际上,Google建立了一个TensorFlow.js传输学习图像分类器代码实验室,也可以完成上述操作。我用两行代码对代码实验室进行了调整,用来复制donottouchyourface.com在下图JSFiddle中所做的工作:
const webcamElement = document.getElementById('webcam');
const classifier = knnClassifier.create();
let net;
async function app() {
console.log('Loading mobilenet..');
// Load the model.
net = await mobilenet.load();
console.log('Successfully loaded model');
// Create an object from Tensorflow.js data API which could capture image
// from the web camera as Tensor.
const webcam = await tf.data.webcam(webcamElement);
// Reads an image from the webcam and associates it with a specific class
// index.
const addExample = async classId => {
for (let x = 50; x > 0; x--) {
// Capture an image from the web camera.
const img = await webcam.capture();
// Get the intermediate activation of MobileNet 'conv_preds' and pass that
// to the KNN classifier.
const activation = net.infer(img, 'conv_preds');
// Pass the intermediate activation to the classifier.
classifier.addExample(activation, classId);
// Dispose the tensor to release the memory.
img.dispose();
// Add some time between images so there is more variance
setTimeout(() => {
console.log("Added image")
}, 100)
}
};
// When clicking a button, add an example for that class.
document.getElementById('class-a').addEventListener('click', () => addExample(0));
document.getElementById('class-b').addEventListener('click', () => addExample(1));
while (true) {
if (classifier.getNumClasses() > 0) {
const img = await webcam.capture();
// Get the activation from mobilenet from the webcam.
const activation = net.infer(img, 'conv_preds');
// Get the most likely class and confidence from the classifier module.
const result = await classifier.predictClass(activation);
const classes = ['notouch', 'touch'];
document.getElementById('console').innerText = `
prediction: ${classes[result.label]}\n
probability: ${result.confidences[result.label]}
`;
// Dispose the tensor to release the memory.
img.dispose();
}
await tf.nextFrame();
}
}
app();
<html>
<head>
<!-- Load the latest version of TensorFlow.js -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs"></script>
<script src="https://cdn.jsdelivr.net/npm/@tensorflow-models/mobilenet"></script>
<script src="https://cdn.jsdelivr.net/npm/@tensorflow-models/knn-classifier"></script>
</head>
<body>
<div id="console">Remember to allow your camera first</div>
<!-- Add an image that we will use to test -->
<video autoplay playsinline muted id="webcam" width="224" height="224"></video>
<button id="class-a">No touch</button>
<button id="class-b">Touch Face</button>
<span id="message"></span>
<!-- Load index.js after the content of the page -->
<script src="index.js"></script>
</body>
</html>
BodyPix方法
如上图所示,我们很难在几秒钟内识别模型。理想情况下,我们可以要求数百个人分享他们在不同环境和位置下触摸和不触摸他们的脸的图像。然后我们可以以此为基础建立一个新的模型。我不清楚是否有这样的标记数据集,但是TensorFlow.js有一个类似的工具—— BodyPix。BodyPix可以识别人并对其身体各个部位(手臂、腿、脸等)进行细分。BodyPix的2.0新版本甚至可以检测姿势,就像PoseNet提供的功能那样。
假设:我们可以使用BodyPix来检测手和脸。当手与脸重叠时,我们就可以判定有脸部接触。
BodyPix足够准确吗?
首先要看模型的质量。如果它无法可靠地检测到手和脸,那它会被弃用。该repo包含一个演示页面,因此很容易测试它是否有效:
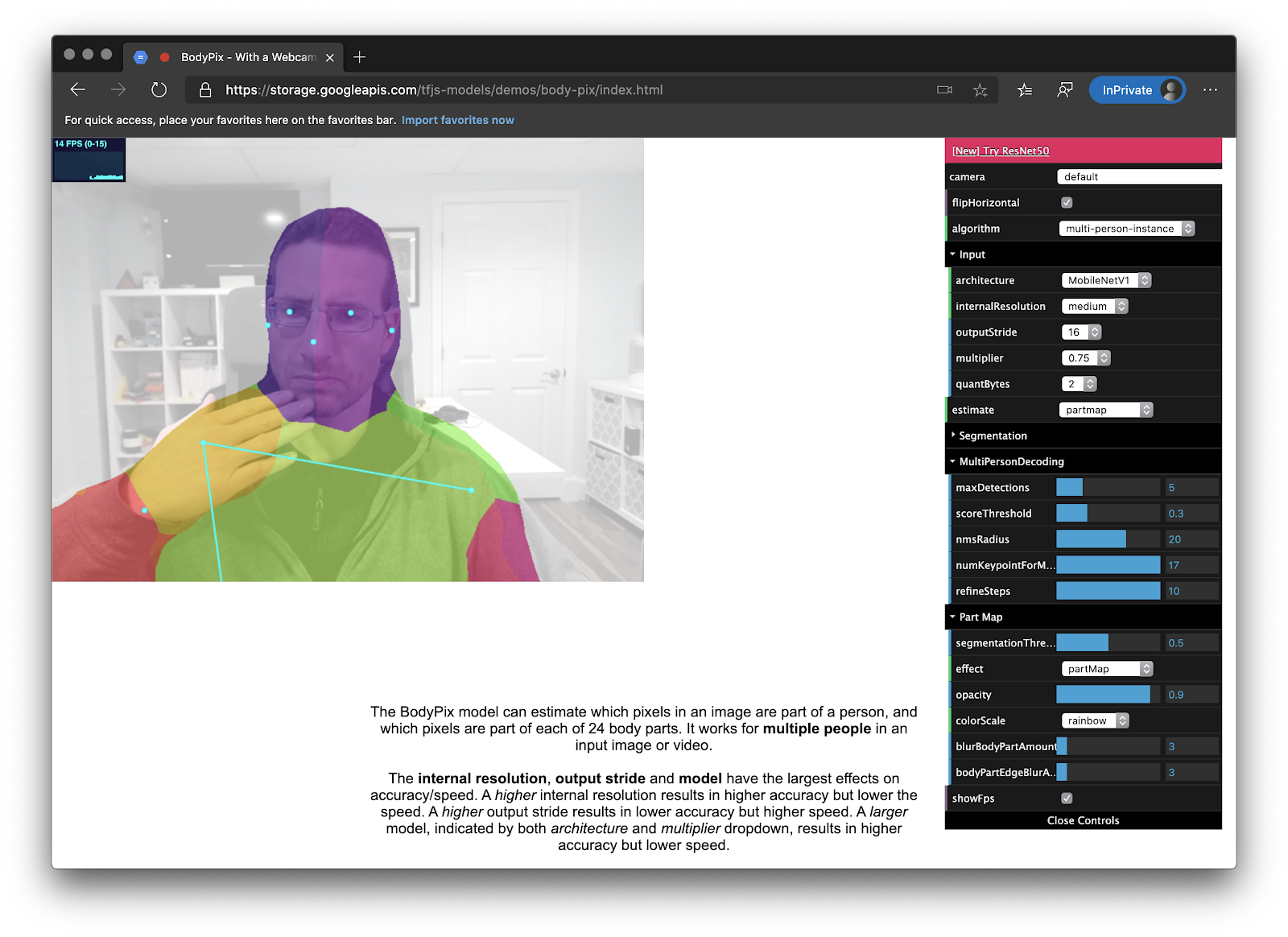 2.0出色地完成了工作,特别是与1.0模型相比。这令我印象深刻。
2.0出色地完成了工作,特别是与1.0模型相比。这令我印象深刻。
使用BodyPix API
该API有以下选项:
PersonSegmentation:将人与画面背景分割,湖面中的所有人戴一个口罩,
segmentMultiPerson:将人与画面背景分割,给每个人都带一个口罩;
segmentPersonParts:将一个或多个人的单个身体部位分割为单个数据集
segmentMultiPersonParts:将一个或多人的身体部位单独设为一组数据集。
我想要的是“ personParts”功能。但是The readme.md警告说segmentMultiPersonParts运行速度较慢,并且它的数据结构更复杂。所以我选择了segmentPersonParts。如果您想要查看所有选项的操作,请移步BodyPix repo上的文档。
执行操作后会返回一个类似于以下内容的对象:
allPoses: Array(1)
0:
keypoints: Array(17)
0: {score: 0.9987769722938538, part: "nose", position: {…}}
1: {score: 0.9987848401069641, part: "leftEye", position: {…}}
2: {score: 0.9993035793304443, part: "rightEye", position: {…}}
3: {score: 0.4915933609008789, part: "leftEar", position: {…}}
4: {score: 0.9960852861404419, part: "rightEar", position: {…}}
5: {score: 0.7297815680503845, part: "leftShoulder", position: {…}}
6: {score: 0.8029483556747437, part: "rightShoulder", position: {…}}
7: {score: 0.010065940208733082, part: "leftElbow", position: {…}}
8: {score: 0.01781448908150196, part: "rightElbow", position: {…}}
9: {score: 0.0034013951662927866, part: "leftWrist", position: {…}}
10: {score: 0.005708293989300728, part: "rightWrist", position: {…}}
...
score: 0.3586419759016922
length: 1
data: Int32Array(307200) [-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, …]
height: 480
width: 640
基本内容包括图像的尺寸、具有特定姿势点的24个身体部位中的每个部位的得分,以及与各个像素或-1对应身体部位的整数数组。姿势点本质上是另一个TensorFlow库PoseNet中提供的准确性较低的版本。
算法随处可见
尽管花了点时间,我最终得出了以下算法:
- 如果图像不包含鼻子和至少一只眼睛的可能性很高,请忽略图像;
- 检查手是否曾经在前一帧中位于脸部部位–每次重叠计数1点;
- 检查手是否在触摸脸部–每次接触计数1点;
- 当以上几项加起来的点数超过阈值时,触发警报。
实时监控
能够实时查看分类器的工作非常有用。BodyPix中包含一些用于绘制姿势点和分段数据的帮助模型的API。如果您要查看所有细分部分,只需将其传递给segmentPersonParts返回的细分对象:
const coloredPartImage = bodyPix.toColoredPartMask(targetSegmentation); const opacity = 0.7; const maskBlurAmount = 0; bodyPix.drawMask( drawCanvas, sourceVideo, coloredPartImage, opacity, maskBlurAmount, flipHorizontal);
我想重点关注手和脸,因此我修改了细分数据,将其只包含上述targetSegmentation中的部分。
另外,我还复制了从keypoints数组中绘制后估计点的代码。
优化
要使该模型在各种设备上都可用是最费时的一部分工作。我们还没有完全解决这个问题。但是只要知道正确的打开方式,就可以完美流畅地运行它。
灵敏度和错误警报
当人脸出现在画面中,该模型就会进行触摸检测。(根据其检测)一只眼睛和一个鼻子就可以认定为一张脸。模型里设定有灵敏度阈值。并且我发现其检测效果非常可靠。所以我将阈值设置得很高。
segmentPerson使用一个配置对象。其中包含有几个影响灵敏度的参数。我使用的两个参数是segmentationThreshold和scoreThreshold。
但是它并不能很好地识别多人场景。遇到这种情况,使用segmentMultiPersonParts更为合适。在配置参数内部,我把maxDetections设置为1。这可以告诉姿势估计器应寻找多少人(但不影响部位检测)。
最后,您可以使用该模型做出几种改变性能的选择,我将在下一部分中介绍。
CPU占用率
BodyPix的CPU占用率很高。我在MacBook上安装了2.9 GHz 6核的Intel Core i9,所以对我来说这不是什么大问题,但该问题在速度较慢的计算机上更为明显。TensorFlow.js也会尽可能利用GPU,因此如果您没有合适的GPU,它会变慢。这在每秒帧数(FPS)速率中体现的很明显。
调整模型参数
通过说明我们知道:BodyPix有许多模型参数,这些模型参数会为了速度牺牲准确性。为了帮助测试这些参数,我添加了4个选项按钮,这些按钮将使用以下设置加载模型。
| Button | outputStride (higher is faster) | Multiplier (lower is faster) |
| Faster | 16 | 0.5 |
| Normal | 16 | 0.75 |
| More accurate | 8 | 0.75 |
| Most accurate | 8 | 1 |
更准确的设置肯定会减少误报。
我们发现:普通版在我的新MacBook上消耗了整个vCPU内核,运行速度约为15 FPS。
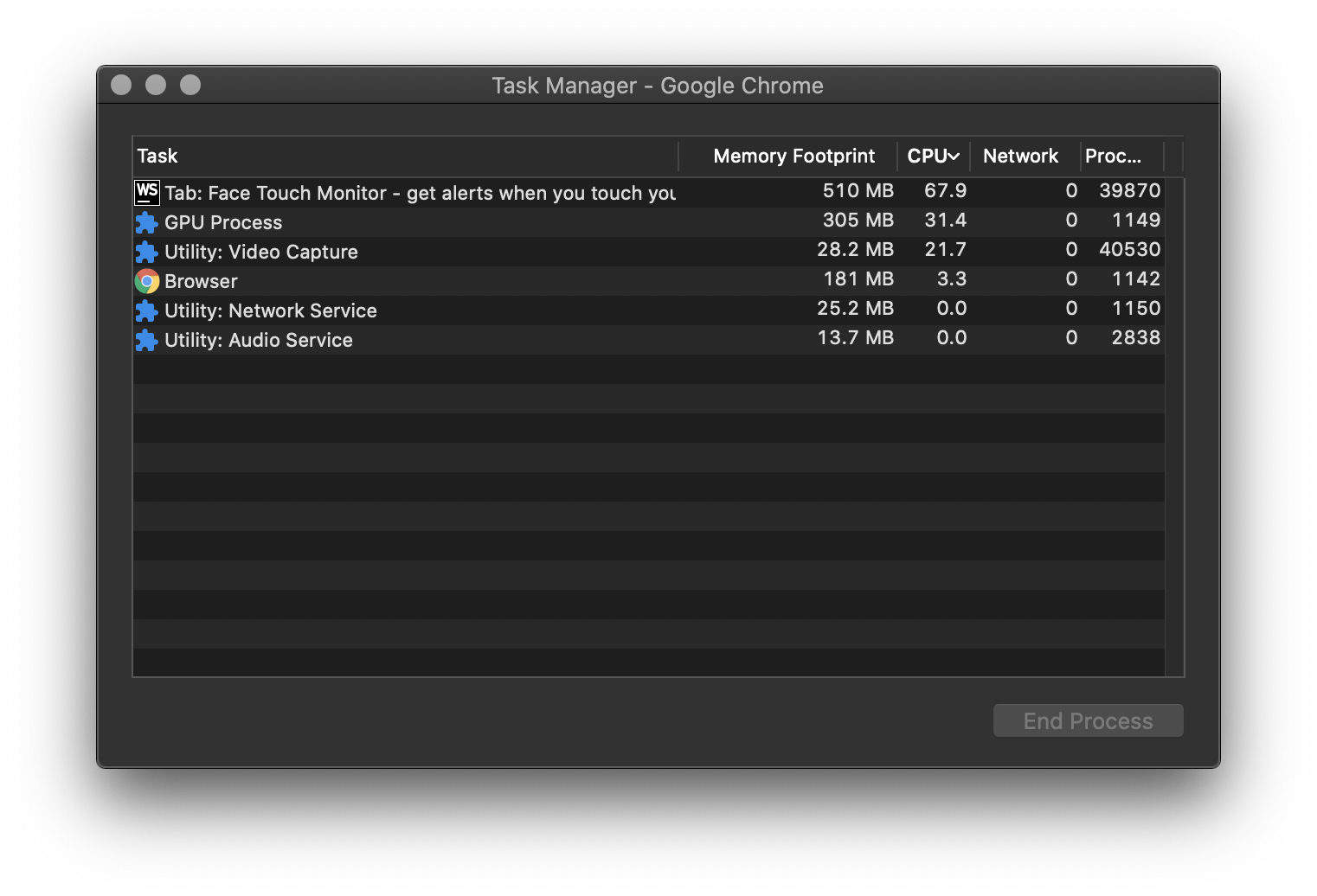
不仅是BodyPix这样。我之前修缮过的MobileNet + KNN分类器示例中也是如此,视频较小,但效果却没有那么好。
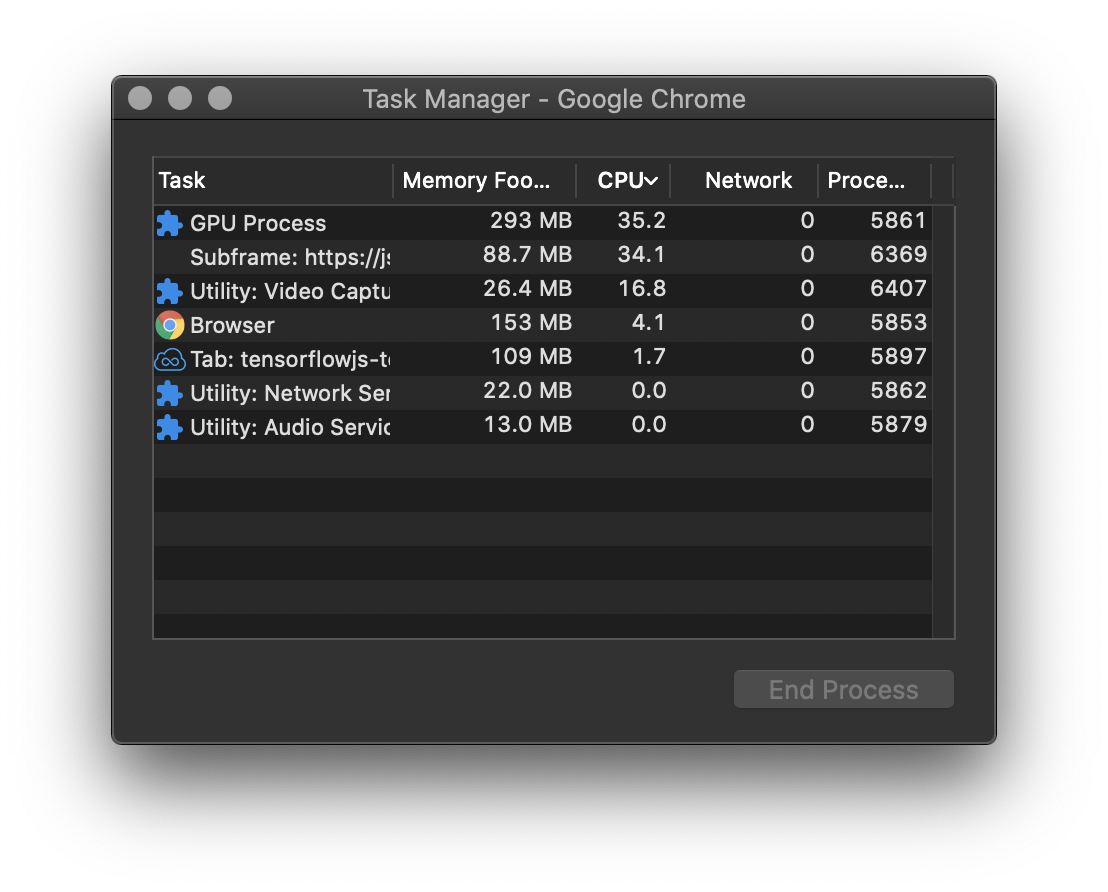
我有一个配备较慢的双核奔腾1.6 GHz的Windows Surface Go,它以5 FPS的速度运行普通版模型。将模型加载到这个电脑上确实需要花费更长的时间。
调整设置会改善CPU和CPS,但对CPU和1或2 FPS的影响仅为几个百分点。这远低于我的预期。
是否可以改善
TensorFlow.js实际上有一个Web Assembly库,其运行速度明显更快。我希望这可以帮助解决CPU消耗问题,但是我遇到了两个问题:
wasm后端仅适用于BodyPix 1.0,但是1.0的检测精度远不及2.0;
我根本无法使其与BodyPix一起加载。
我可以解决第二个问题,但是如果它仍然不能很好地工作,那也没有什么意义。我相信将不久的将来官方会推出支持BodyPix 2.0的tfjs-backend-wasm版本。
节流问题
我注意到当视频在屏幕上不再活跃时,其动作会变缓慢。在速度较慢的机器上表现更为明显。所以大家不要忘记,当打开太多标签页时,为了节省资源,浏览器会限制不活跃的标签页。我想出了一些应对的方法,之后会进一步探索。

浏览器支持
毫无疑问,因为TensorFlow.js是Google项目,所以在Chrome中运行模型效果最好。Firefox和Edge(Edgium)中也能正常工作。但是我没能将其加载到Safari中。
实验
您可以轻松地在facetouchmonitor.com上自己进行尝试,或观看下面的视频演示:
所有代码均可在GitHub上找到,网址为https://github.com/webrtchacks/facetouchmonitor。
在过去几天的实验里,该模型运作良好。
不要摸脸!
其实我可以做更多的调整,但是在我和其他人所做的大多数测试中,模型运行的效果都很好。也鼓励大家提出更多的修改和优化意见。
我希望这可以督促您不要经常触摸脸部,来帮助您保持健康。如果您实在想要摸脸,请您考虑戴个头盔吧!
原文地址:https://webrtchacks.com/stop-touching-your-face-with-browser-tensorflow-js/
文章作者:chad hart